AEWS 4회차는 EKS Observability에 대해 다룬다. 이전에 kOps 때 다뤘던 모니터링 및 대쉬보드에 대한 내용을 주로 다룰 예정이다.
0. 환경 구성
환경 구성은 매번 실습 때 가시다님이 제공해주시는 One Click Yaml을 통해 배포를 진행한다.
이번 실습 때는 이전에 시도했다가 성공하지 못한 Cross-Account ExternalDNS을 통해 진행하려고 한다. Cross-Account ExternalDNS 설정은 아래와 같이 진행할 예정이다. 여기서 Route53 Account는 Route53 Record을 관리하는 Account이고 EKS Account는 실습에 사용하는 EKS을 배포하는 Account이다.
EKS Account에 Policy&Role을 생성한다.
Policy는 Route53 Account에서 만들 Role에 대해 AssumeRole하는 Action으로 만든다.
Role은 Trust relationships을 작성할 때 EKS에서 확인 가능한 OIDC Provider URL을 참고해서 입력하고 Permission Policy는 위에서 만든 Policy을 선택한다
#Policy 생성
#Policy Name : external-dns-policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::ROUTE53Account:role/external-dns-cross-account"
}
]
}
#Role 생성
#Role Name : external-dns
#Trust relationships
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::EKSAccount:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
},
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::EKSAccount:oidc-provider/oidc.eks.ap-northeast-2.amazonaws.com/id/2FD..."
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"oidc.eks.ap-northeast-2.amazonaws.com/id/2FD...:sub": "system:serviceaccount:kube-system:external-dns"
}
}
}
]
}Route53 Account에도 Role을 생성해준다.
Permission Policy는 나는 AmazonRoute53FullAccess을 줬지만 필요에 따라 최소한의 정책을 설정해줘도 된다. 그리고 Trust relationships 작성 시에 EKSAccount의 위에서 만든 Role인 external-dns Role에 대해 sts:AssumeRole 허용해줬다.
#Role 생성
#Role Name : external-dns-cross-account
#Trust relationships
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::EKSAccount:role/external-dns"
},
"Action": "sts:AssumeRole"
}
]
}위와 같이 Role을 만들어줬다면 externaldns 배포에 사용되는 yaml 파일을 수정한 후 배포를 진행하면 된다.
ServiceAccount kind에서 annotations 부분에 EKSAccount의 Role ARN을 입력해준다.
Deployment kind에서는 Containers args 부분을 찾은 뒤 Route53 Account의 Role ARN을 입력해준다.
#externaldns.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: external-dns
namespace: kube-system
#아래 내용 삽입
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::EKSAccount:role/external-dns
#
labels:
app.kubernetes.io/name: external-dns
.......
apiVersion: apps/v1
kind: Deployment
args:
- --source=service
- --source=ingress
- --domain-filter=${MyDomain} # will make ExternalDNS see only the hosted zones matching provided domain, omit to process all available hosted zones
- --provider=aws
#아래 내용 삽입
- --aws-assume-role=arn:aws:iam::Route53Account:role/external-dns-cross-account
#
#- --policy=upsert-only # would prevent ExternalDNS from deleting any records, omit to enable full synchronization
- --aws-zone-type=public # only look at public hosted zones (valid values are public, private or no value for both)
- --registry=txt
- --txt-owner-id=${MyDnzHostedZoneId}
...........이후 ExternalDNS 배포를 진행하면 Cross Account ExternalDNS을 배포할 수 있게 된다.
이때 Route53 Hosted Zone ID는 수동으로 입력해주었다.
ExternalDNS 및 kube-ops-view을 설치 후 ExternalDNS Log을 확인해보면 제대로 조회 및 등록이 된 것을 확인할 수 있다. 해당 URL로 접근하면 페이지도 제대로 나오는 것을 알 수 있다.
# ExternalDNS
MyDomain=bs-yang.com
echo "export MyDomain=bs-yang.com" >> /etc/profile
MyDnzHostedZoneId=Z030...
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml
MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst < externaldns.yaml | kubectl apply -f -
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
kubectl patch svc -n kube-system kube-ops-view -p '{"spec":{"type":"LoadBalancer"}}'
kubectl annotate service kube-ops-view -n kube-system "external-dns.alpha.kubernetes.io/hostname=kubeopsview.$MyDomain"
echo -e "Kube Ops View URL = http://kubeopsview.$MyDomain:8080/#scale=1.5"
# Log 확인
kubectl logs -n kube-system external-dns-
time="2023-05-16T06:56:38Z" level=info msg="Instantiating new Kubernetes client"
time="2023-05-16T06:56:38Z" level=info msg="Using inCluster-config based on serviceaccount-token"
time="2023-05-16T06:56:38Z" level=info msg="Created Kubernetes client https://10.100.0.1:443"
time="2023-05-16T06:56:38Z" level=info msg="Assuming role: arn:aws:iam::Route53Account:role/external-dns-cross-account"
time="2023-05-16T06:56:39Z" level=info msg="Applying provider record filter for domains: [bs-yang.com. .bs-yang.com.]"
time="2023-05-16T06:56:40Z" level=info msg="All records are already up to date"
time="2023-05-16T06:57:39Z" level=info msg="Applying provider record filter for domains: [bs-yang.com. .bs-yang.com.]"
time="2023-05-16T06:57:39Z" level=info msg="Desired change: CREATE cname-kubeopsview.bs-yang.com TXT [Id: /hostedzone/Z030...]"
time="2023-05-16T06:57:39Z" level=info msg="Desired change: CREATE kubeopsview.bs-yang.com A [Id: /hostedzone/Z030...]"
time="2023-05-16T06:57:39Z" level=info msg="Desired change: CREATE kubeopsview.bs-yang.com TXT [Id: /hostedzone/Z030...]"
time="2023-05-16T06:57:40Z" level=info msg="3 record(s) in zone bs-yang.com. [Id: /hostedzone/Z030...] were successfully updated"
LB Controller와 EBS csi driver, gp3 sc, EFS sc 등을 설치 및 설정하면서 환경 설정을 마무리한다.
# AWS LB Controller
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
# EBS csi driver 설치 확인
eksctl get addon --cluster ${CLUSTER_NAME}
kubectl get pod -n kube-system -l 'app in (ebs-csi-controller,ebs-csi-node)'
kubectl get csinodes
# gp3 스토리지 클래스 생성
kubectl get sc
cat <<EOT > gp3-sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp3
allowVolumeExpansion: true
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
allowAutoIOPSPerGBIncrease: 'true'
encrypted: 'true'
EOT
kubectl apply -f gp3-sc.yaml
kubectl get sc
# EFS csi driver 설치
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
helm repo update
helm upgrade -i aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver \
--namespace kube-system \
--set image.repository=602401143452.dkr.ecr.${AWS_DEFAULT_REGION}.amazonaws.com/eks/aws-efs-csi-driver \
--set controller.serviceAccount.create=false \
--set controller.serviceAccount.name=efs-csi-controller-sa
# EFS 스토리지클래스 생성 및 확인
curl -s -O https://raw.githubusercontent.com/kubernetes-sigs/aws-efs-csi-driver/master/examples/kubernetes/dynamic_provisioning/specs/storageclass.yaml
sed -i "s/fs-92107410/$EfsFsId/g" storageclass.yaml
kubectl apply -f storageclass.yaml
kubectl get sc efs-sc1. EKS Console
EKS에 대한 옵저빌리티 중 EKS Console에서 확인하는 내용이다. EKS라고 이름은 되어있지만 EKS Console 상에서 확인하는 대부분의 내용은 k8s API을 통해 호출된다.
예전에 혼자 EKS을 배포하는 테스트를 할 때 EKS 배포는 했는데 EKS Console에서 상세한 내용을 확인할 수 없는 문제가 있었다. 분명 Admin User였어서 권한의 문제는 없어야하는데 아래와 같은 메시지가 나오면서 확인되지 않는 부분이 있었다.
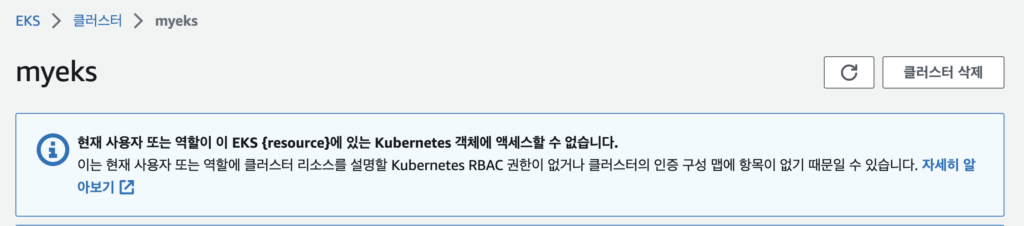
이런 메시지가 나오는 이유는 아무리 AdminAccess 권한을 갖고 있더라도 eks cluster role을 부여받지 않으면 저런 메시지가 호출되게 된다.
물론 EKS 배포에 사용한 iam user의 경우 자신이 EKS Cluster Owner이기 때문에 해당 권한을 갖고있지 않더라도 EKS Console 및 kubectl 등 명령어를 통해 확인하는데는 문제가 없다.
해당 Admin User에 EKS Rolebinding을 해주면 문제 없이 EKS Console 등에서 확인이 가능하다.
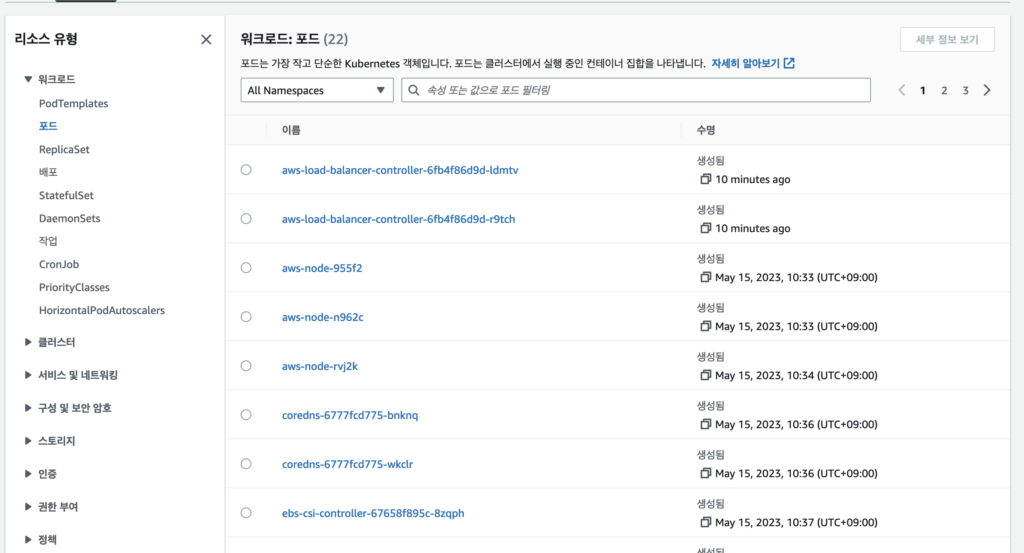
EKS Console 에서 확인 가능한 내용은 다양하다. Pod 정보를 포함하여 k8s에서 조회가 가능한 대부분의 내용을 확인할 수 있다고 보면 된다.
2. Logging in EKS
EKS에서의 Logging의 경우 CP, node, App 등에 대한 로깅이 가능하다.
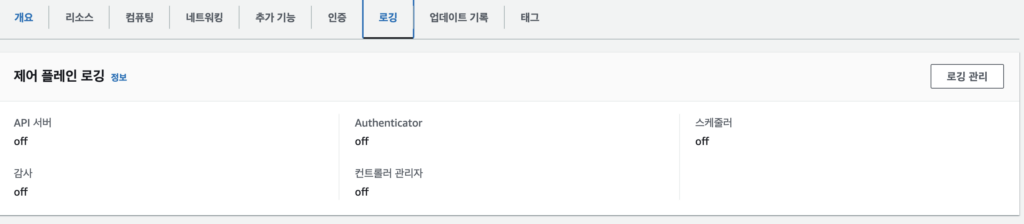
CP 로깅 종류는 API Server, Authenticator, Audit, Controller Manager, Scheduler가 있다. 기본적으로는 로깅 Off로 되어있고 이걸 aws cli을 통해 활성화 할 수 있다.
CP 로깅의 자세한 내용은 아래 링크를 참고 가능하다.
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/control-plane-logs.html
# 모든 로깅 활성화
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
# 로그 그룹 확인
aws logs describe-log-groups | jq
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short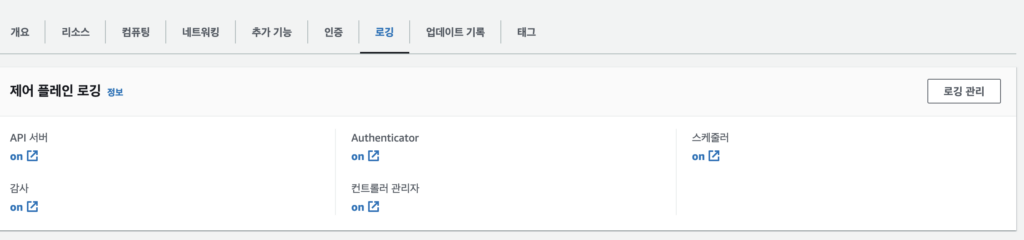
Container Pod 로깅도 가능하다. Pod 로깅을 테스트하기 위해 Helm에서 nginx 서버를 배포한다.
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml
# 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# (참고) 삭제 시
helm uninstall nginx설치하고 브라우저에서 정상적으로 페이지가 열리는 것을 확인했다면 별도의 모니터링용 터미널을 하나 더 띄우고 반복접속과 모니터링 결과를 확인한다. 접속이 하나 들어올 때마다 로그에도 내용이 추가되는 것을 확인할 수 있었다. 이렇게 간략하게 Pod의 Application 로그를 확인하는 내용을 진행해보았다.
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
# 로그 모니터링
kubectl logs deploy/nginx -f
# 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
total 0
lrwxrwxrwx 1 root root 11 Apr 24 10:13 access.log -> /dev/stdout
lrwxrwxrwx 1 root root 11 Apr 24 10:13 error.log -> /dev/stderr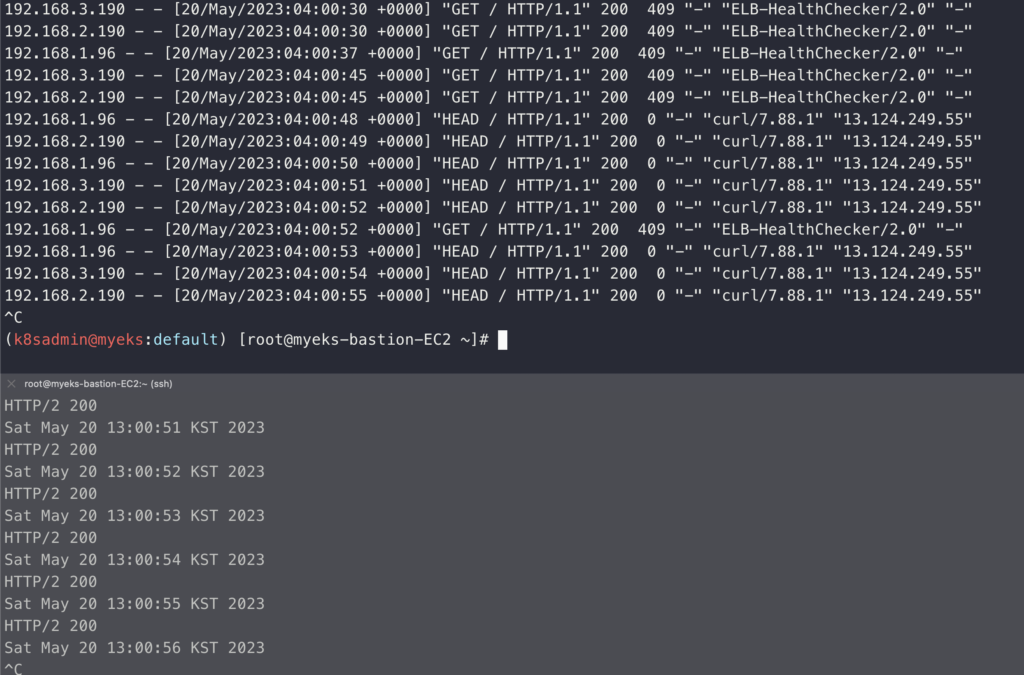
3. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
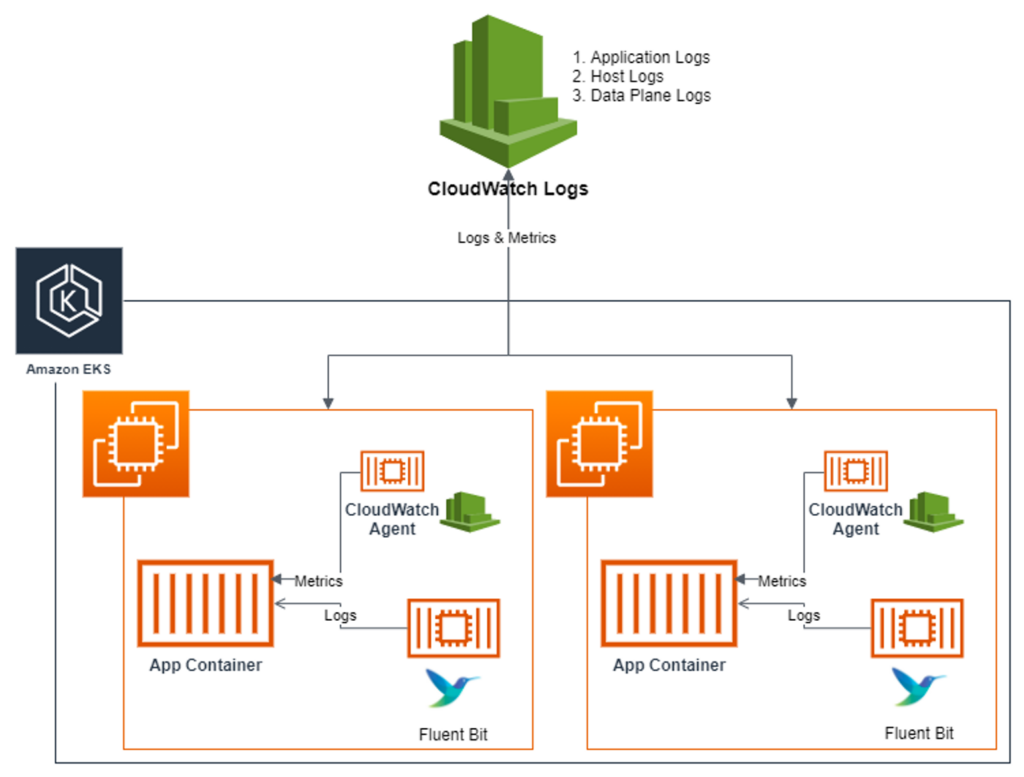
CCI(CloudWatch Container Insight)는 노드에 Cloudwatch Agent 파드와 Fluent Bit 파드가 데몬셋으로 배치되어 Metrics와 Log을 수집할 수 있다.
Fluent Bit는 Cloudwatch Logs에 로그를 전송하기 위한 데몬셋이다.
Fluent Bit 데몬셋으로 로그를 수집하고 시각화하는 과정은 3단계로 작동하게 되는데, 수집-저장-시각화의 단계로 이루어진다.
[수집] : Fluent Bit 파드를 데몬셋으로 동작시키고 아래 3가지 종류의 로그를 CW Logs에 전송
1) /aws/containerinsights/Cluster_Name/application : /var/log/containers에 포함 된 모든 로그 파일과 각 컨테이너/파드 로그
2) /aws/containerinsights/Cluster_Name/host : /var/log/dmesg, /var/log/secure, /var/log/message의 로그 파일들과 노드 로그
3) /aws/containerinsights/Cluster_Name/dataplane : /var/log/journal의 로그 파일과 k8s dataplane 로그
[저장] : CW Logs에 로그를 저장한다. 로그 그룹 별 로그 보존 기간 설정 가능하다.
[시각화] : CW의 LogsInsights를 사용하여 대상 로그를 분석하고 CW의 대쉬보드를 시각화한다.
간략하게 보기 위한 그림은 아래와 같다.
이후 로그들을 열어보기 위해 사전에 Node의 로그 위치를 확인해 본다.
Application, host, dataplane 위치를 각각 확인해본다.
# Application 로그 위치 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/containers; echo; done
>>>>> 192.168.3.182 <<<<<
/var/log/containers
├── aws-load-balancer-controller-6fb4f86d9d-r9tch_kube-system_aws-load-balancer-controller-8de8d0ceaa922575f336ded6a7b5e30f43656765829d268ddb01f36539e80cb3.log -> /var/log/pods/kube-system_aws-load-balancer-controller-6fb4f86d9d-r9tch_48c648fb-83c1-499e-9453-e0ddb65cf088/aws-load-balancer-controller/0.log
├── aws-node-955f2_kube-system_aws-node-c36d95a4abb2e33245350b1acf670b63208e7ad0353b87e39d10a6c32904f643.log -> /var/log/pods/kube-system_aws-node-955f2_fe7aaf5b-f4bd-425b-a099-cdc8821c6844/aws-node/1.log
├── aws-node-955f2_kube-system_aws-node-d05cfd440860db1074b84ead88b5dd79575ded2b078bcb3ca2cb5d2bd1094ecc.log -> /var/log/pods/kube-system_aws-node-955f2_fe7aaf5b-f4bd-425b-a099-cdc8821c6844/aws-node/0.log
...
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -al /var/log/containers; echo; done
>>>>> 192.168.3.182 <<<<<
total 16
drwxr-xr-x 2 root root 8192 May 20 03:54 .
drwxr-xr-x 10 root root 4096 May 17 00:02 ..
lrwxrwxrwx 1 root root 143 May 17 01:20 aws-load-balancer-controller-6fb4f86d9d-r9tch_kube-system_aws-load-balancer-controller-8de8d0ceaa922575f336ded6a7b5e30f43656765829d268ddb01f36539e80cb3.log -> /var/log/pods/kube-system_aws-load-balancer-controller-6fb4f86d9d-r9tch_48c648fb-83c1-499e-9453-e0ddb65cf088/aws-load-balancer-controller/0.log
lrwxrwxrwx 1 root root 92 May 17 00:02 aws-node-955f2_kube-system_aws-node-c36d95a4abb2e33245350b1acf670b63208e7ad0353b87e39d10a6c32904f643.log -> /var/log/pods/kube-system_aws-node-955f2_fe7aaf5b-f4bd-425b-a099-cdc8821c6844/aws-node/1.log
...
# host 로그 위치 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/ -L 1; echo; done
>>>>> 192.168.3.182 <<<<<
/var/log/
├── amazon
├── audit
├── aws-routed-eni
...
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -la /var/log/; echo; done
>>>>> 192.168.3.182 <<<<<
total 4132
drwxr-xr-x 10 root root 4096 May 17 00:02 .
drwxr-xr-x 19 root root 268 May 17 01:21 ..
drwxr-xr-x 3 root root 17 May 15 01:33 amazon
drwx------ 2 root root 61 May 20 01:18 audit
drwxr-xr-x 2 root root 69 May 15 01:34 aws-routed-eni
...
# dataplane 로그 위치 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/journal -L 1; echo; done
>>>>> 192.168.3.182 <<<<<
/var/log/journal
├── ec2179c4f3e906eda92ce733733bd5d0
└── ec221453e78b0818ba3c9f00233580cbCloudwatch Container Insight를 설치해서 로그 수집을 하고 내용을 확인해볼 예정이다.
# 설치
FluentBitHttpServer='On'
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
FluentBitReadFromTail='On'
curl -s https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f -
# 설치 확인
kubectl get-all -n amazon-cloudwatch
kubectl get ds,pod,cm,sa -n amazon-cloudwatch
kubectl describe clusterrole cloudwatch-agent-role fluent-bit-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding fluent-bit-role-binding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l name=cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ss -tnlp | grep fluent-bit; echo; done
# cloudwatch-agent 설정 확인
kubectl describe cm cwagentconfig -n amazon-cloudwatch
{
"agent": {
"region": "ap-northeast-2"
},
"logs": {
"metrics_collected": {
"kubernetes": {
"cluster_name": "myeks",
"metrics_collection_interval": 60
}
},
"force_flush_interval": 5
}
}
# Fluent Bit Cluster Info 확인
kubectl get cm -n amazon-cloudwatch fluent-bit-cluster-info -o yaml | yh
apiVersion: v1
data:
cluster.name: myeks
http.port: "2020"
http.server: "On"
logs.region: ap-northeast-2
read.head: "Off"
read.tail: "On"
kind: ConfigMap
...
# Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인
## 설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
kubectl describe cm fluent-bit-config -n amazon-cloudwatch
...
application-log.conf:
----
[INPUT]
Name tail
Tag application.*
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*, /var/log/containers/aws-node*, /var/log/containers/kube-proxy*
...
[FILTER]
Name kubernetes
Match application.*
Kube_URL https://kubernetes.default.svc:443
...
[OUTPUT]
Name cloudwatch_logs
Match application.*
region ${AWS_REGION}
log_group_name /aws/containerinsights/${CLUSTER_NAME}/application
...
# (참고) 삭제
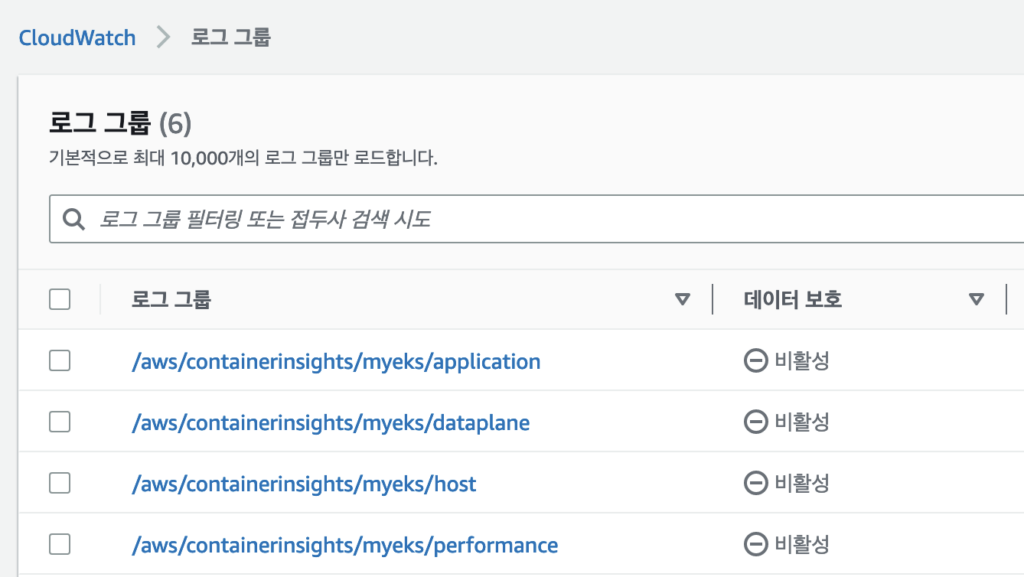
curl -s https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${CLUSTER_NAME}'/;s/{{region_name}}/'${AWS_DEFAULT_REGION}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl delete -f -Cloudwatch Container Insight을 설치하고 CW에서 로그와 매트릭 수집이 되고 있는지 확인 가능하다. 로그 그룹에 들어가보면 위에서 설정한 내용들의 로그그룹이 생성 된 것을 확인할 수 있다. 마찬가지로 Container Insight에 들어가면 메트릭도 확인할 수 있다.
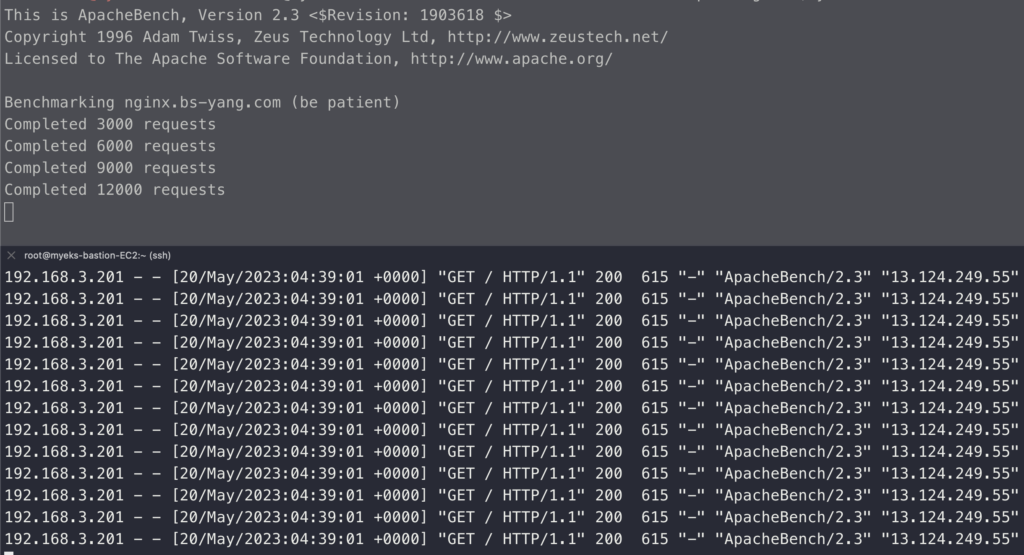
로그가 제대로 나오는지 보기위해 부하를 발생시키고 로그에서 확인을 해본다.
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/
# 파드 직접 로그 모니터링
kubectl logs deploy/nginx -f부하 발생을 시키고 동시에 직접 로그 모니터링을 실행한다. 로그 모니터링을 같이 하는 이유는 이후 로그 그룹에서 확인할 때 동일하게 내용이 나오는지 보기 위함이다.
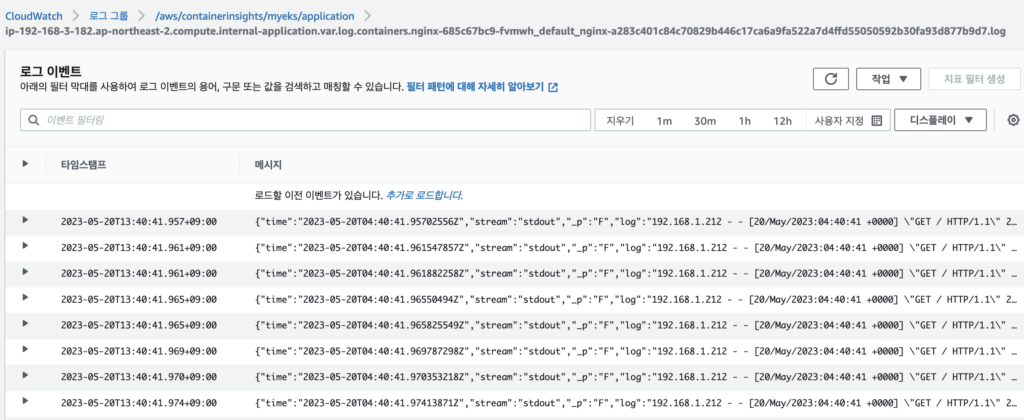
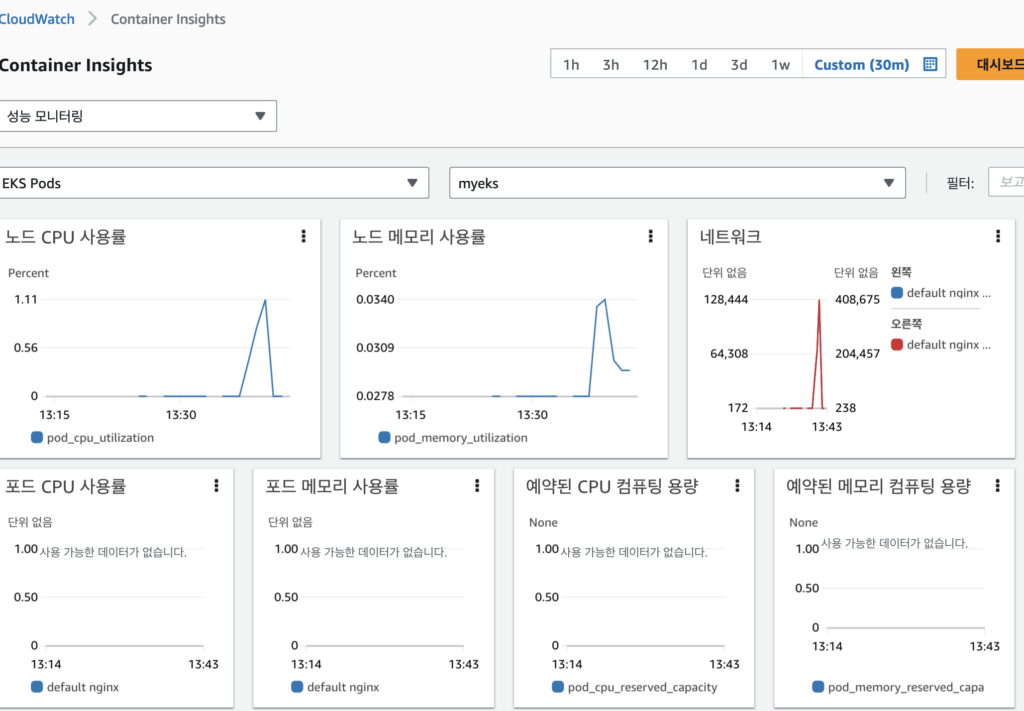
다시 콘솔로 돌아가서 로그 그룹의 내용과 매트릭도 확인해보았다.매트릭은 CPU 사용률이나 기타 다양한 내용들을 확인할 수 있으니 Pod을 실행하고 부하 발생 테스트 등을 할 때 같이 모니터링을 하면 좋을 것 같다.
4. Metrics-server & kwatch & botkube
Metrics-Server : kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소로 cAdvisor(kubelet에 포함 된 커네티어 메트릭을 수집, 집계 및 노출하는 데몬)을 통해 데이터를 가져온다.
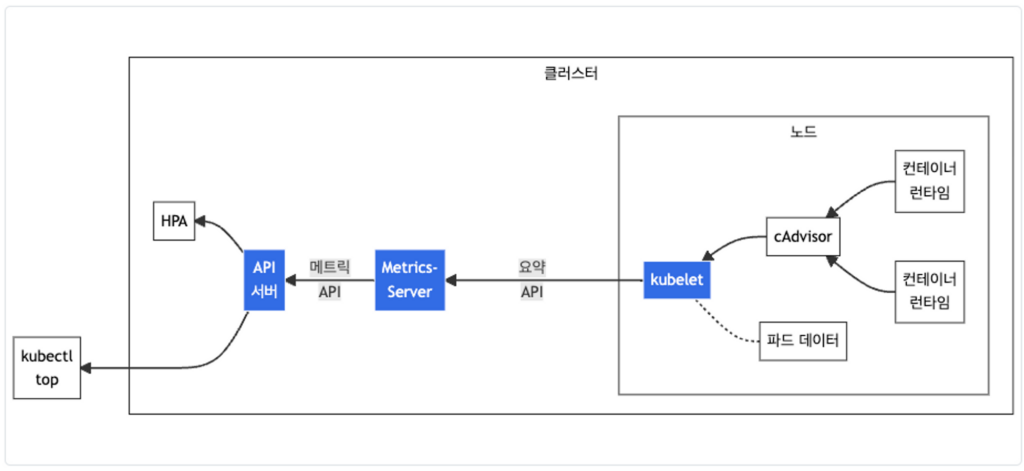
metrics-server을 배포하고 설치 내용을 확인해본다.
메트릭 값의 경우 15초 간격으로 cAdvisor을 통해 가져오게 되어있다. 그러니 최초 배포 후 일정 시간 후에 확인해보도록 하자.
# 배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-6bf466fbf5-zxjb2 1/1 Running 0 46s
kubectl api-resources | grep metrics
nodes metrics.k8s.io/v1beta1 false NodeMetrics
pods metrics.k8s.io/v1beta1 true PodMetrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
NAME SERVICE AVAILABLE AGE
v1beta1.metrics.k8s.io kube-system/metrics-server True 85s
# 노드 메트릭 확인
kubectl top node
# 파드 메트릭 확인
kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
amazon-cloudwatch cloudwatch-agent-4k4mm 7m 33Mi
amazon-cloudwatch cloudwatch-agent-krmd4 7m 34Mi
amazon-cloudwatch cloudwatch-agent-x6bz4 6m 30Mi
...
kubectl top pod -n kube-system --sort-by='cpu'
NAME CPU(cores) MEMORY(bytes)
kube-ops-view-558d87b798-6z5bt 12m 38Mi
metrics-server-6bf466fbf5-zxjb2 5m 19Mi
ebs-csi-controller-67658f895c-8zqph 5m 60Mi
...
kubectl top pod -n kube-system --sort-by='memory'
NAME CPU(cores) MEMORY(bytes)
ebs-csi-controller-67658f895c-8zqph 6m 60Mi
ebs-csi-controller-67658f895c-lm6wq 2m 52Mi
aws-node-n962c 5m 47Mi
...kwatch : Kubernetes(K8s) 클러스터의 모든 변경 사항을 모니터링하고, 실행 중인 앱의 충돌을 실시간으로 감지하고, 채널(Slack, Discord 등)에 즉시 알림을 게시하도록 도와주는 서비스이다. 지난 kOps 스터디 때도 다뤘던 서비스이다.
나는 스터디에서 제공한 Slack 채널이 아닌 별도 관리하는 채널에 테스트를 진행할 예정이다.
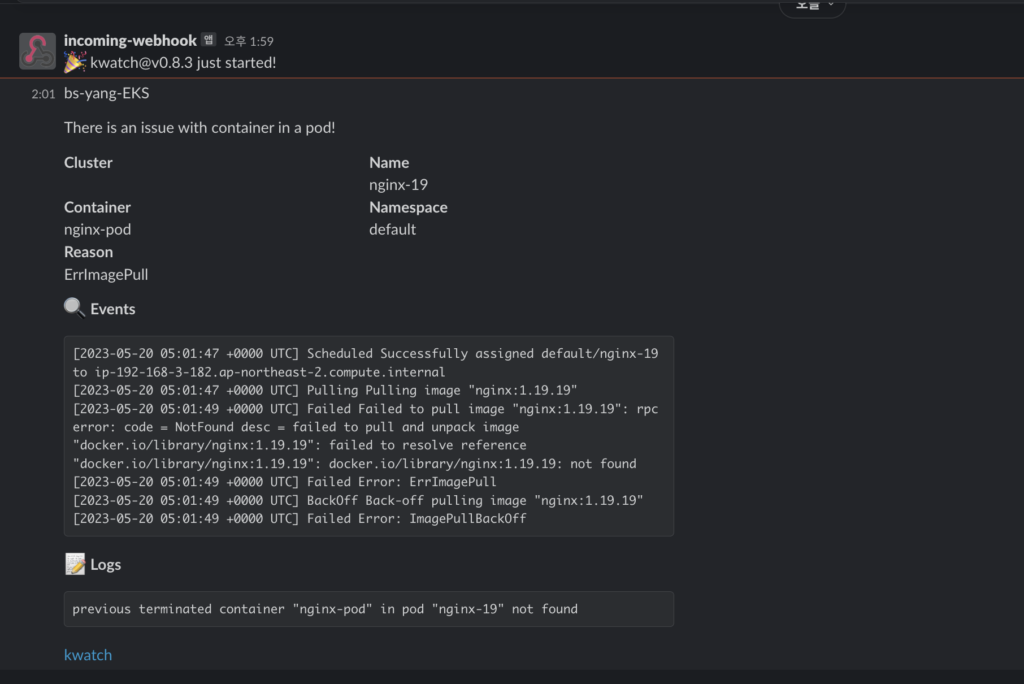
일전에 만들어둔 WebHookURL을 입력해서 Configmap을 생성하고 kwatch 배포를 진행했다. 배포가 되면 내 슬랙 채널에 메시지가 뜨는 것을 확인할 수 있다.
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'MyWebhook URL'
title: $NICK-EKS
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml
일부러 잘못 된 이미지의 파드를 배포해서 오류 메시지를 수신하는지 확인해볼 예정이다.
이미지 버전 정보가 잘못 된 이미지를 배포하면 바로 오류가 발생하고 슬랙에도 메시지가 오는 것을 볼 수 있다.
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w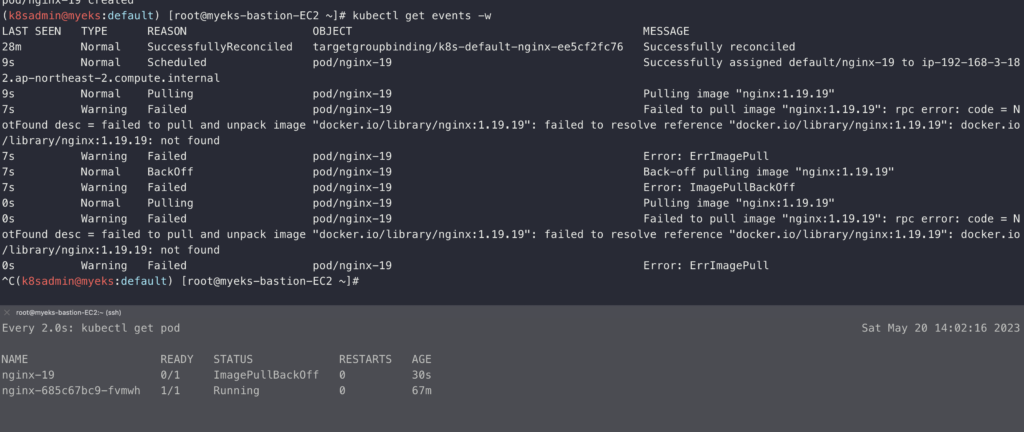
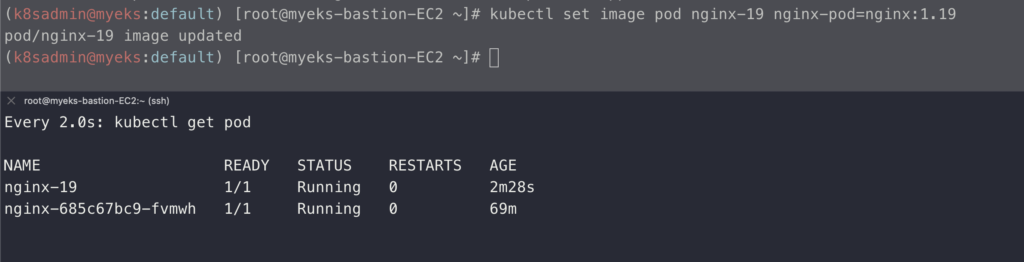
위 내용을 수정해보도록 한다.
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
위 명령어로 잘못된 이미지 태그 정보를 수정했더니 바로 pod가 Running 상태로 변경된 것을 확인할 수 있다.
botkube : k8s 클러스터에서 알림 및 이벤트 관리를 위한 오픈소스 도구로 클러스터의 상태 변화, 오류 및 경고 등을 적시에 감지하고 조치를 취할 수 있는 서비스. 커스터마이즈가 가능하여 각각의 알림 룰을 정의하고 원하는 이벤트 유형에 대한 알림을 선택적으로 받을 수 있다. 이를 통해 클러스터의 상태 및 이벤트를 효과적으로 관리하고 모니터링할 수 있게 된다.
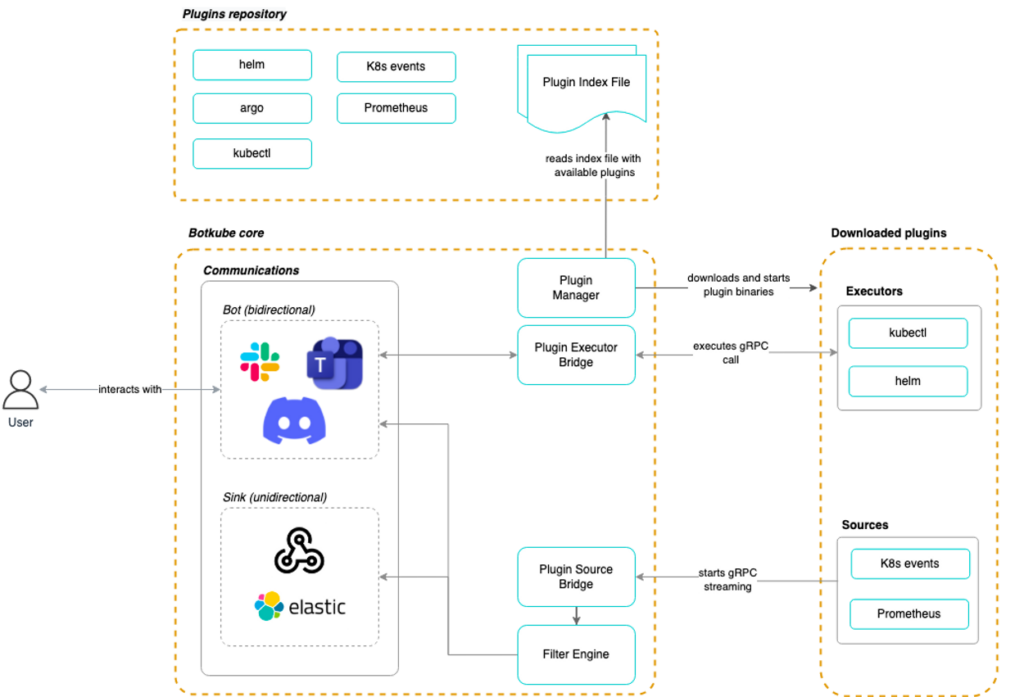
kwatch 때처럼 별도의 슬랙 채널에서 테스트할 예정이라 Slack App을 생성해야 한다. App 생성 방법은 공식 사이트를 참고하였다. https://docs.botkube.io/installation/slack/
# Slack API Token 설정
export SLACK_API_BOT_TOKEN='MySlackBotToken'
export SLACK_API_APP_TOKEN='MySlackAppToken'
# repo 추가
helm repo add botkube https://charts.botkube.io
helm repo update
# 변수 지정
export ALLOW_KUBECTL=true
export ALLOW_HELM=true
export SLACK_CHANNEL_NAME=study
#
cat <<EOT > botkube-values.yaml
actions:
'describe-created-resource': # kubectl describe
enabled: true
'show-logs-on-error': # kubectl logs
enabled: true
executors:
k8s-default-tools:
botkube/helm:
enabled: true
botkube/kubectl:
enabled: true
EOT
# 설치
helm install --version v1.0.0 botkube --namespace botkube --create-namespace \
--set communications.default-group.socketSlack.enabled=true \
--set communications.default-group.socketSlack.channels.default.name=${SLACK_CHANNEL_NAME} \
--set communications.default-group.socketSlack.appToken=${SLACK_API_APP_TOKEN} \
--set communications.default-group.socketSlack.botToken=${SLACK_API_BOT_TOKEN} \
--set settings.clusterName=${CLUSTER_NAME} \
--set 'executors.k8s-default-tools.botkube/kubectl.enabled'=${ALLOW_KUBECTL} \
--set 'executors.k8s-default-tools.botkube/helm.enabled'=${ALLOW_HELM} \
-f botkube-values.yaml botkube/botkube
# 참고 : 삭제 시
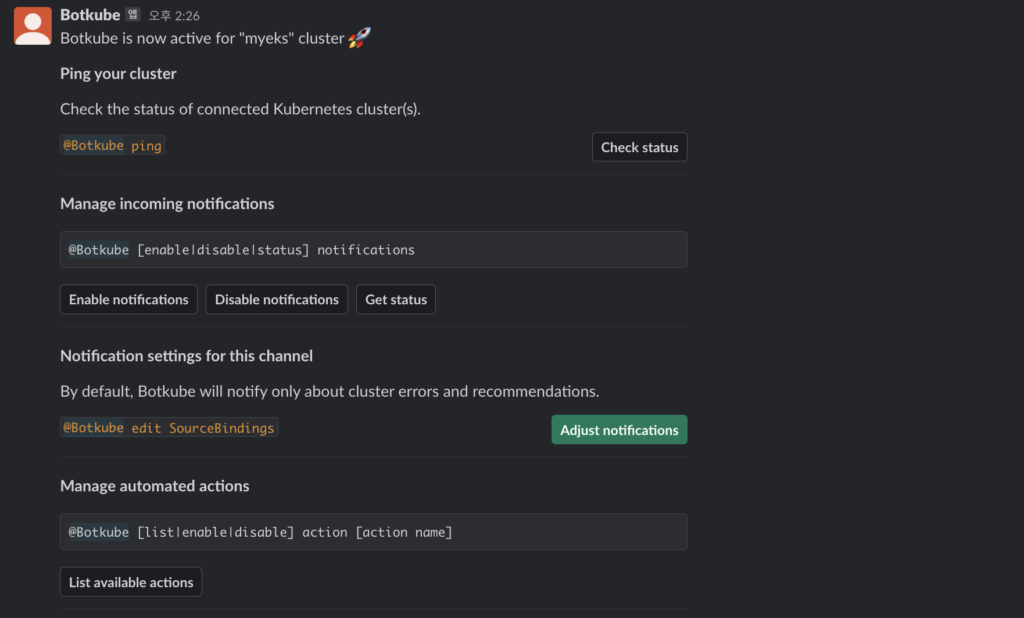
helm uninstall botkube --namespace botkube설치가 잘 됐다면 앱 표시에 Botkube가 생성된 것을 확인할 수 있고 채널에 들어가서 초대를 하면 (이상한 게 디폴트 채널을 설정해놔도 바로 입장하지 않았다.) 안내메시지를 호출해준다.
botkube가 제대로 설치되었으니 이제 테스트를 진행해보도록 한다.
슬랙 채널에서 아래 메시지들을 입력하면 botkube가 응답해주는 것을 볼 수 있다. 직접 터미널을 통해 접속하기 어려운 환경일 때 간단한 명령어 등으로 현황을 확인할 수 있는 좋은 방법이라고 생각이 든다. 물론 보안적인 문제는 있을 수 있으니 비공개채널에 만들어서 사용하는 게 좋을 것 같다.
# 연결 상태, notifications 상태 확인
@Botkube ping
@Botkube status notifications
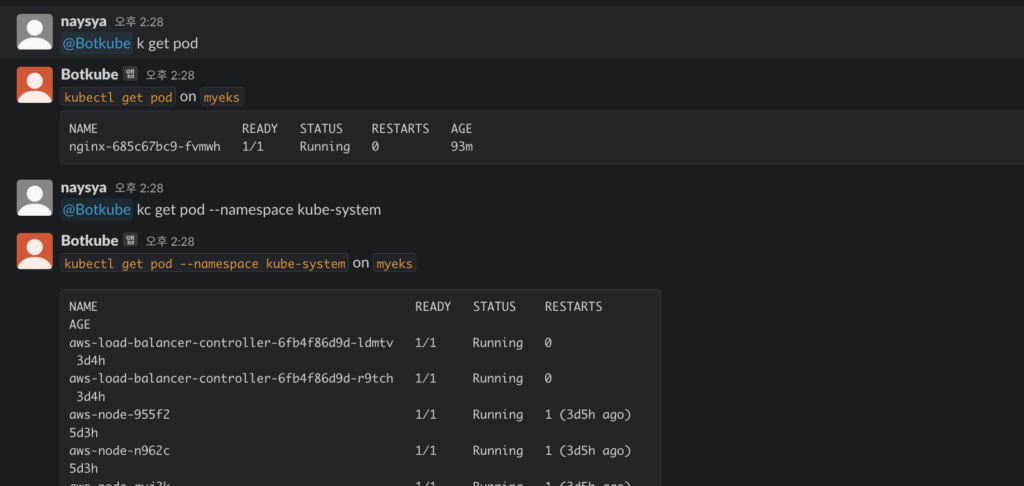
# 파드 정보 조회
@Botkube k get pod
@Botkube kc get pod --namespace kube-system
@Botkube kubectl get pod --namespace kube-system -o wide
# Actionable notifications
@Botkube kubectl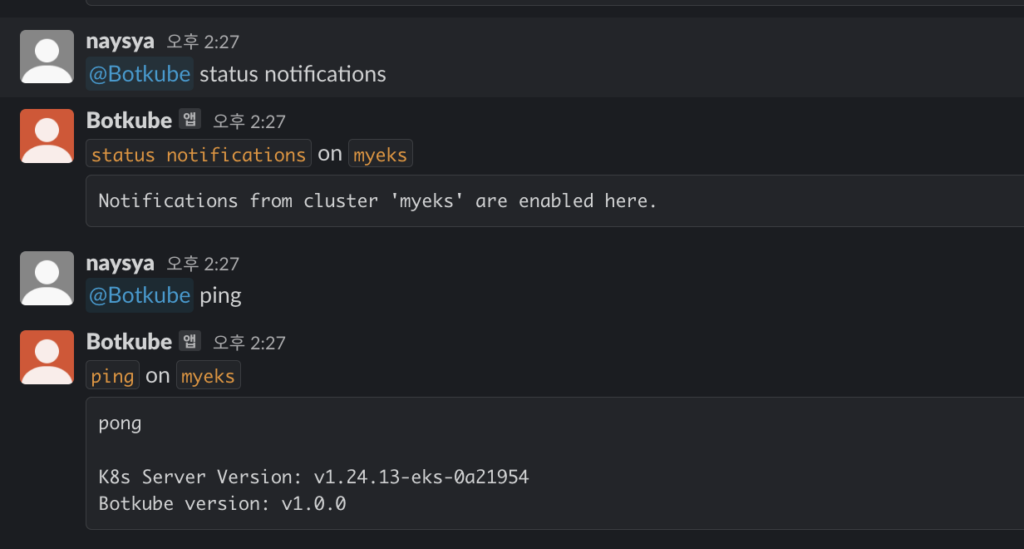
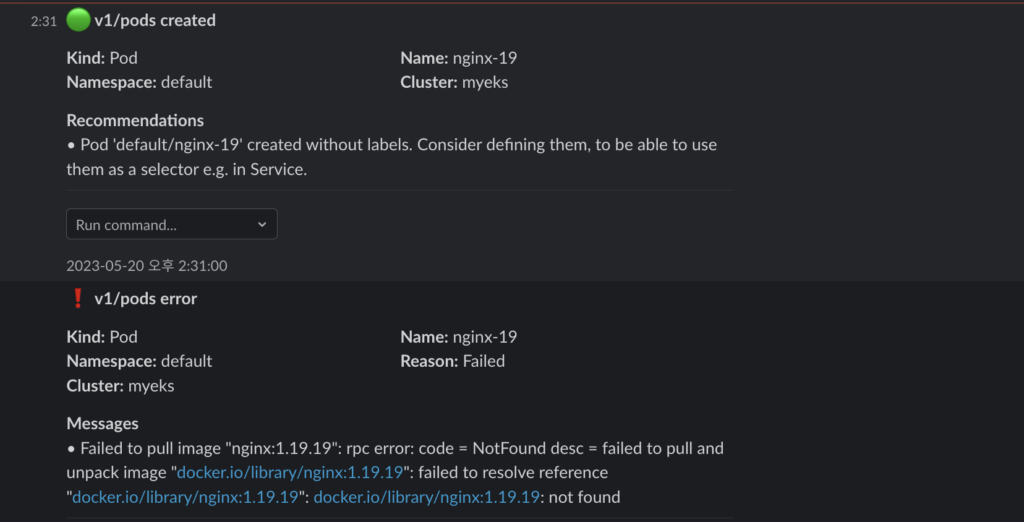
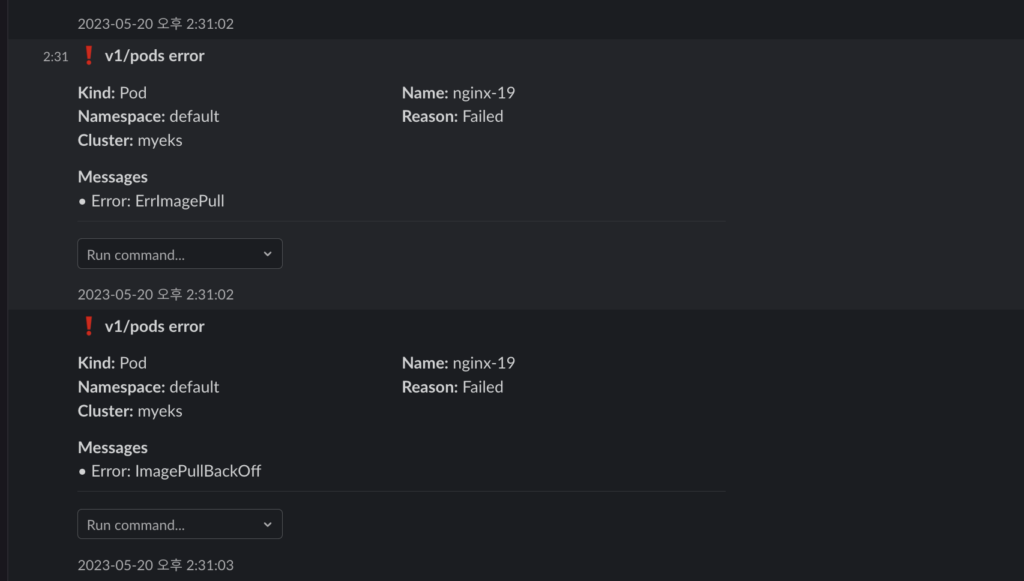
kwatch에서의 테스트처럼 일부러 잘못 된 이미지를 배포해서 알림을 받아보도록 한다.
배포를 진행하면 바로 알림이 오는 것을 알 수 있다. 알림의 속도는 kwatch보다 빠른 것 같다.
5. Prometheus-stack
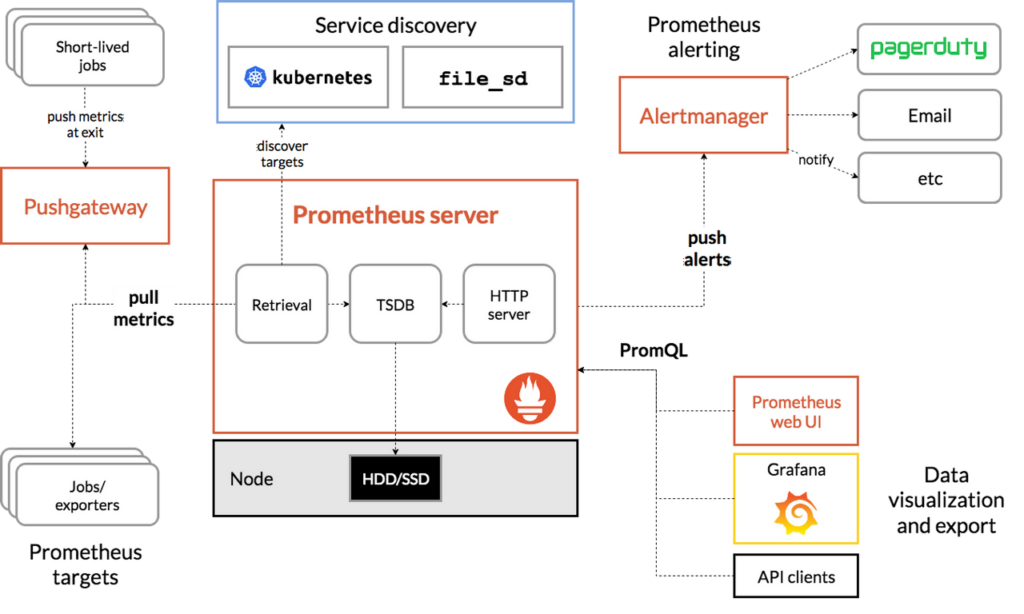
Prometheus : Soundcloud에서 제작한 오픈소스 시스템 Monitoring, Alert 툴킷이다.
특징으로는 간단한 구조를 갖추고 있어 수월한 운영을 할 수 있고 강력한 쿼리 기능을 통해 다양한 결과값을 도출할 수 있다. 뒤에 실습할 Grafana와의 조합을 통해 시각화를 할 수 있고 ELK와 같은 로깅 방식이 아니라 시스템으로부터 모니터링 지표를 수집하여 저장하는 시스템이다. 자세한 구조는 아래 그림과 같다.
Prometheus-stack : kube-prometheus-stack은 Kubernetes 매니페스트, Grafana 대시보드, 문서 및 스크립트와 결합된 Prometheus 규칙을 수집하여 Prometheus Operator를 사용하여 Prometheus에서 엔드 투 엔드 Kubernetes 클러스터 모니터링을 쉽게 운영할 수 있다.
Prometheus-stack을 설치해보도록 한다.
# 모니터링 : 터미널 새로 띄워서 확인
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo $CERT_ARN
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: myapssword
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
# alertmanager:
# ingress:
# enabled: true
# ingressClassName: alb
# hosts:
# - alertmanager.$MyDomain
# paths:
# - /*
# annotations:
# alb.ingress.kubernetes.io/scheme: internet-facing
# alb.ingress.kubernetes.io/target-type: ip
# alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
# alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
# alb.ingress.kubernetes.io/success-codes: 200-399
# alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
# alb.ingress.kubernetes.io/group.name: study
# alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.27.2 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2023-05-20 14:40:34.552674361 +0900 KST deployed kube-prometheus-stack-45.27.2 v0.65.1
kubectl get pod,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/kube-prometheus-stack-grafana-665bb8df8f-547f2 3/3 Running 0 51s
pod/kube-prometheus-stack-kube-state-metrics-5d6578867c-p9g6b 1/1 Running 0 51s
pod/kube-prometheus-stack-operator-74d474b47b-br78c 1/1 Running 0 51s
...
kubectl get-all -n monitoring
NAME NAMESPACE AGE
configmap/kube-prometheus-stack-alertmanager-overview monitoring 68s
configmap/kube-prometheus-stack-apiserver monitoring 68s
configmap/kube-prometheus-stack-cluster-total monitoring 68s
configmap/kube-prometheus-stack-grafana monitoring 68s
...
kubectl get prometheus,servicemonitors -n monitoring
NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
prometheus.monitoring.coreos.com/kube-prometheus-stack-prometheus v2.42.0 1 1 True True 80s
NAME AGE
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver 80s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns 80s
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-grafana 80s
...
kubectl get crd | grep monitoring
(k8sadmin@myeks:default) [root@myeks-bastion-EC2 ~]# kubectl get crd | grep monitoring
alertmanagerconfigs.monitoring.coreos.com 2023-05-20T05:40:32Z
alertmanagers.monitoring.coreos.com 2023-05-20T05:40:32Z
podmonitors.monitoring.coreos.com 2023-05-20T05:40:32Z
probes.monitoring.coreos.com 2023-05-20T05:40:32Z
prometheuses.monitoring.coreos.com 2023-05-20T05:40:33Z
prometheusrules.monitoring.coreos.com 2023-05-20T05:40:33Z
servicemonitors.monitoring.coreos.com 2023-05-20T05:40:33Z
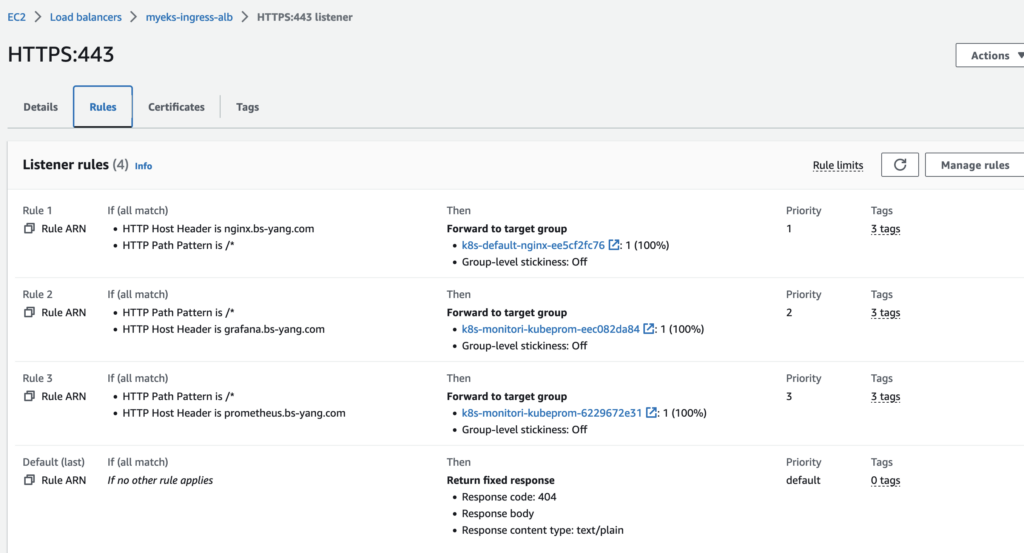
thanosrulers.monitoring.coreos.com 2023-05-20T05:40:33Z설치하고 ALB을 확인하면 하나의 리스너(443)에 다수의 규칙이 생성 된 것을 확인할 수 있다. 이게 가능한 이유는 배포 yaml 파일의 anontation 부부분에 아래와 같이 group.name을 study로 다 통일시켰기 때문이다.
alb.ingress.kubernetes.io/group.name: study이렇게 되면 ALB 자원은 하나만 생성 및 관리해도 되기 때문에 편리하다. 동일한 목적과 수명주기를 갖고 관리하는 서비스들은 위와 같은 방법으로 생성하는 것이 좋을 것ㄱ ㅏㅌ다.
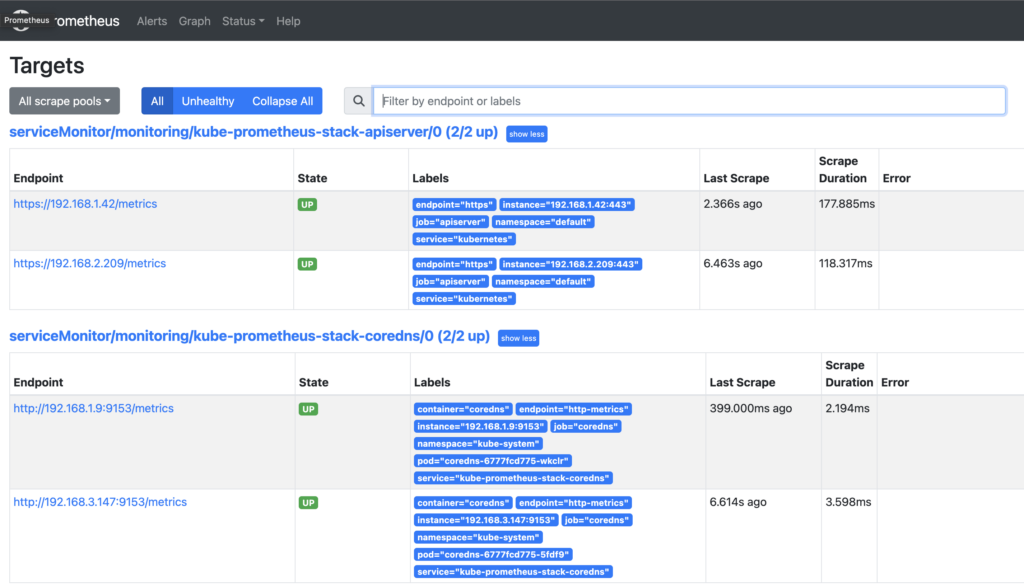
프로메테우스의 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 경로에 다양한 메트릭 정보를 노출한다. 이후 프로메테우스는 해당 경로에 HTTP GET 호출을 하게 되고 TSDB 형식으로 데이터를 저장한다.
ALB 리스너에서 도메인 주소도 확인했다면 프로메테우스에 접속해서 간단하게 확인해보도록 한다. 아래와 같이 데이터가 잘 보인다면 수집 및 출력이 잘 되는 것이다.
6. Grafana
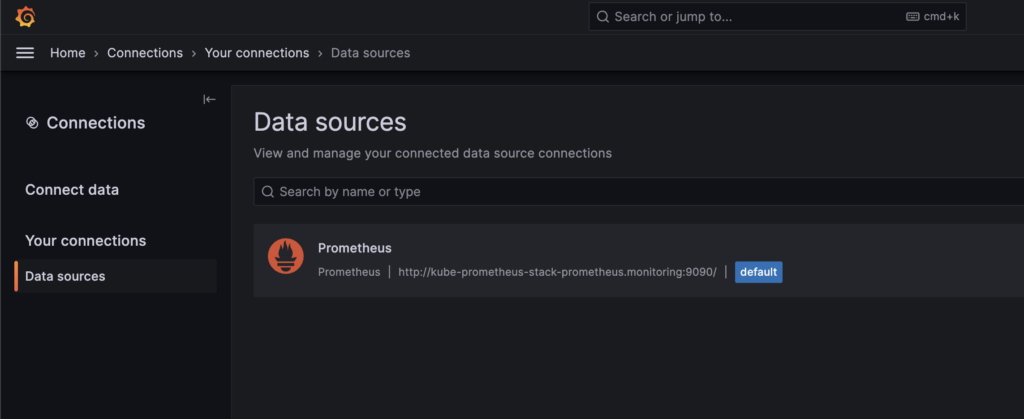
그라파나는 위에서 설명한 프로메테우스가 수집하고 TSDB로 저장한 데이터를 시각화하는 서비스이다. 시각화 솔루션이기 때문에 자체적으로 데이터를 저장하지는 않고 Datasource라고 불리는 수집 데이터를 연결하여 시각화해주는 기능을 제공한다.
프로메테우스 스택으로 설치했기 때문에 그라파나에는 기본적으로 프로메테우스가 Datasource로 추가되어 있다. 별도로 추가하지 않아도 그라파나에서는 위에서 설치한 프로메테우스의 저장 데이터를 불러올 수 있다는 뜻이다.
그라파나에서 확인한 프로메테우스 서비스 주소를 통해 방금 생성한 Pod의 수집을 확인할 수 있다.
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
Server: 10.100.0.10
Address: 10.100.0.10#53
Name: kube-prometheus-stack-prometheus.monitoring.svc.cluster.local
Address: 10.100.32.51
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
* Trying 10.100.32.51:9090...
* Connected to kube-prometheus-stack-prometheus.monitoring (10.100.32.51) port 9090 (#0)
> GET /graph HTTP/1.1
> Host: kube-prometheus-stack-prometheus.monitoring:9090
> User-Agent: curl/8.0.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Sat, 20 May 2023 06:01:06 GMT
< Content-Length: 734
< Content-Type: text/html; charset=utf-8
<
* Connection #0 to host kube-prometheus-stack-prometheus.monitoring left intact
<!doctype html><html lang="en"><head><meta charset="utf-8"/><link rel="shortcut icon" href="./favicon.ico"/><meta name="viewport" content="width=device-width,initial-scale=1,shrink-to-fit=no"/><meta name="theme-color" content="#000000"/><script>const GLOBAL_CONSOLES_LINK="",GLOBAL_AGENT_MODE="false",GLOBAL_READY="true"</script><link rel="manifest" href="./manifest.json" crossorigin="use-credentials"/><title>Prometheus Time Series Collection and Processing Server</title><script defer="defer" src="./static/js/main.c1286cb7.js"></script><link href="./static/css/main.cb2558a0.css" rel="stylesheet"></head><body class="bootstrap"><noscript>You need to enable JavaScript to run this app.</noscript><div id="root"></div></body></html>
# 삭제
kubectl delete pod netshoot-pod우선 Dashobard을 생성한다. 추천 받은 Dashobard 목록 중 한국어 버전으로 나온 걸 추가해볼 생각이다.
Dashboard->Import을 선택한다.
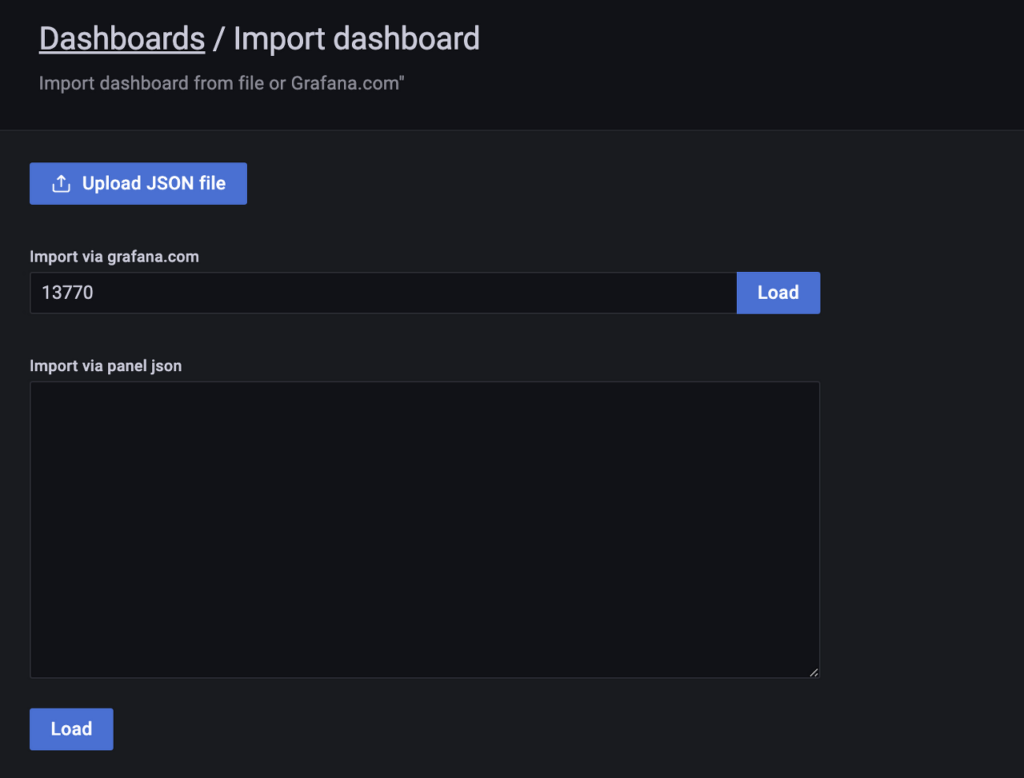
Import via Grafana.com에 추천 받은 Dashboard의 번호를 입력한다. 여기서는 13770을 입력하고 Load을 클릭한다.
Name과 Data Source을 확인하고 Import을 클릭한다.
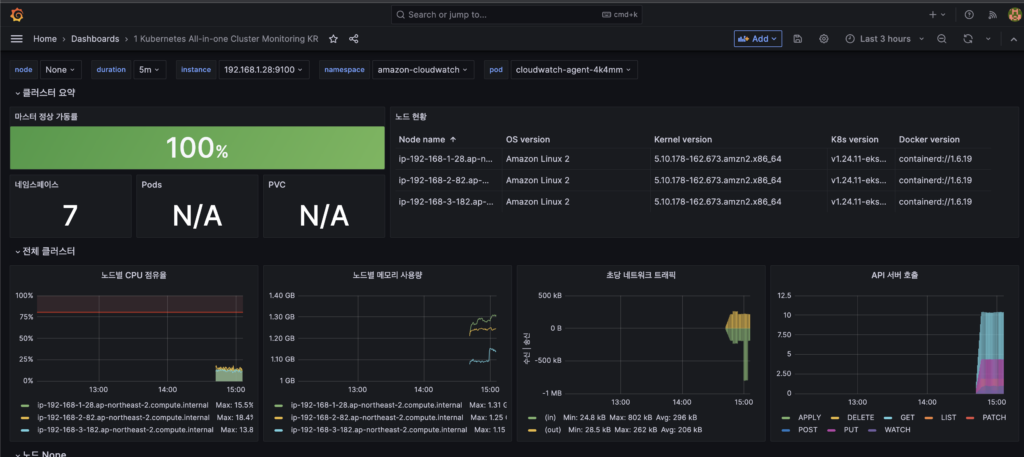
몇 번의 클릭만으로 훌륭한 대쉬보드를 가져올 수 있게 됐다. 여기서 불필요한 건 제거하고 필요하다고 생각되는 걸 추가하는 식으로 나만의 Dashboard을 꾸밀 수 있다.
Application 대쉬보드를 테스트해보기 위해 nginx을 배포해서 테스트해볼 예정이다.
# 모니터링
watch -d kubectl get pod
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
# 확인
kubectl get pod,svc,ep
NAME READY STATUS RESTARTS AGE
pod/nginx-85fc957979-lp8tk 2/2 Running 0 29s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 5d4h
service/nginx NodePort 10.100.212.109 <none> 80:31864/TCP,9113:31740/TCP 134m
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.1.42:443,192.168.2.209:443 5d4h
endpoints/nginx 192.168.2.105:9113,192.168.2.105:8080 134m
kubectl get servicemonitor -n monitoring nginx
NAME AGE
nginx 44s
kubectl get servicemonitor -n monitoring nginx -o json | jq
{
"apiVersion": "monitoring.coreos.com/v1",
"kind": "ServiceMonitor",
"metadata": {
"annotations": {
"meta.helm.sh/release-name": "nginx",
"meta.helm.sh/release-namespace": "default"
...
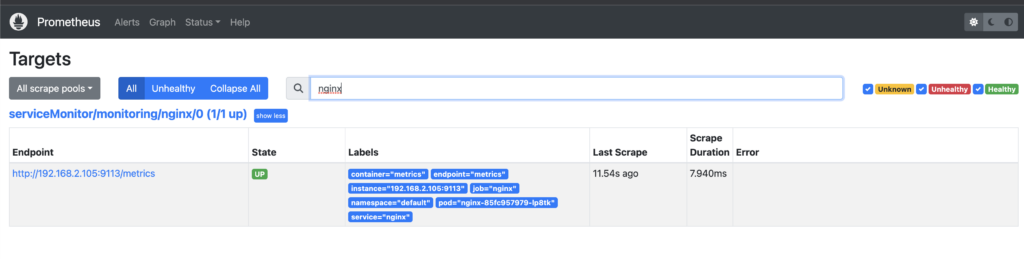
# 메트릭 확인 >> 프로메테우스에서 Target 확인
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
NAME READY STATUS RESTARTS AGE
nginx-85fc957979-lp8tk 2/2 Running 0 2m20s
kubectl describe pod -l app.kubernetes.io/instance=nginx
Name: nginx-85fc957979-lp8tk
Namespace: default
Priority: 0
Service Account: default
Node: ip-192-168-2-82.ap-northeast-2.compute.internal/192.168.2.82
Start Time: Sat, 20 May 2023 15:08:18 +0900
...
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done프로메테우스에서도 nginx에 대한 메트릭 정보를 확인할 수 있고 해당 데이터를 그래프로 표현해서 볼 수도 있다.
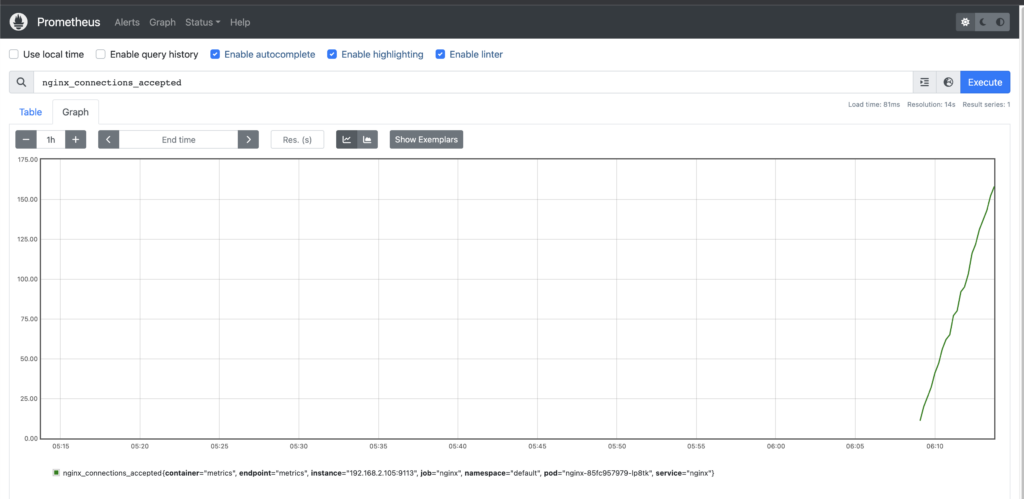
메트릭 수집이 정상적으로 되는 것을 확인했으니 이를 Grafana에서 확인해보도록 하겠다.
위에서 Dashboard을 Import할 때와 같은 방식으로 Import ID는 12708을 사용해서 생성한 대쉬보드이다. 요청 수나 Active Connection 수 등을 확인할 수 있다. 앞서 Prometheus에서 확인한 Connections_active와 동일한 모양임을 알 수 있다.
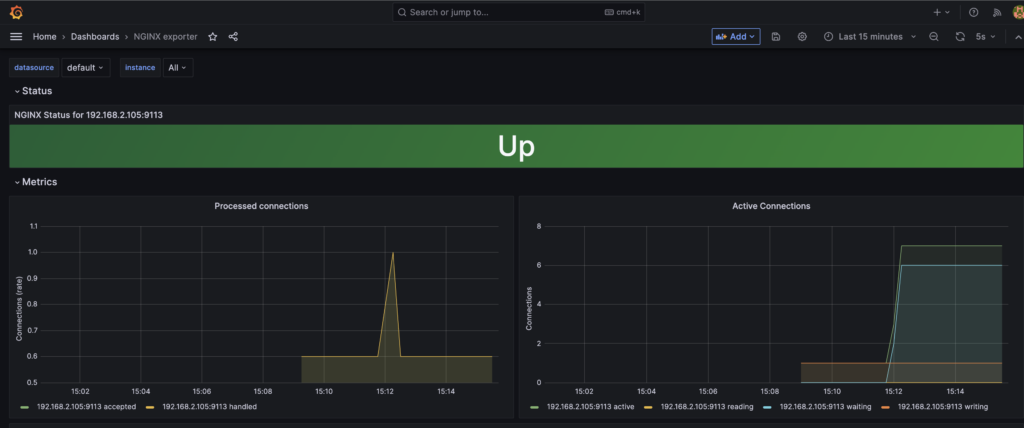
Prometheus에서 수집되는 데이터를 바탕으로 Grafana에서 시각화할 수 있는 것을 확인할 수 있었다.
7. kubecost
kubecost : k8s 클러스터의 비용 분석 및 관리를 위한 오픈 소스 도구로 Kubecost를 사용하면 Kubernetes 클러스터의 리소스 사용량, 비용, 예상 비용 등을 실시간으로 모니터링하고 분석할 수 있다.
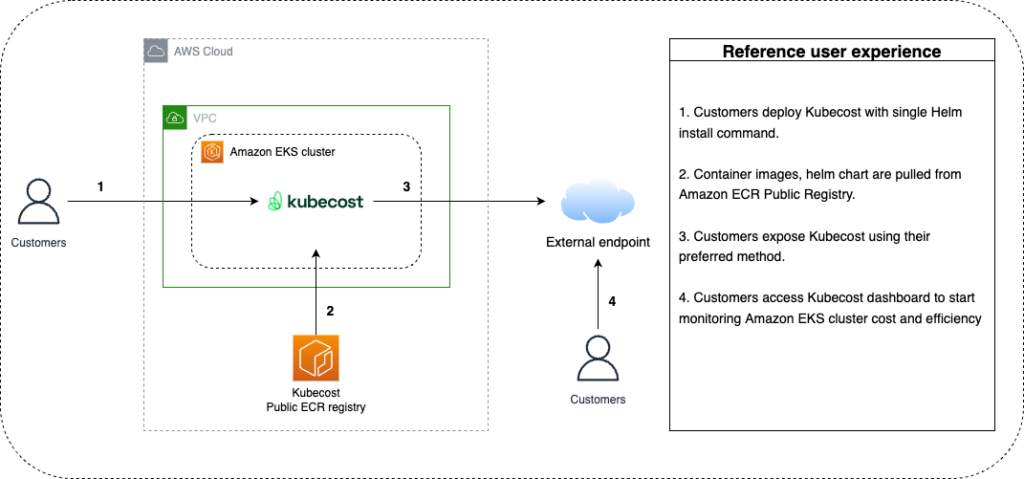
kubecost을 설치한다. 다만, 설치를 하더라도 bastion 환경에서 바로 대쉬보드를 볼 수는 없기 때문에 이를 Loadbalancer에 연결하는 작업을 이후에 진행해주었다.
# kubecost 설치 진행 : 버전은 https://gallery.ecr.aws/kubecost/cost-analyzer 에서 최신 버전 확인
export VERSION="1.103.3"
helm upgrade -i kubecost \
oci://public.ecr.aws/kubecost/cost-analyzer --version="$VERSION" \
--namespace kubecost --create-namespace \
-f https://raw.githubusercontent.com/kubecost/cost-analyzer-helm-chart/develop/cost-analyzer/values-eks-cost-monitoring.yaml \
--set prometheus.configmapReload.prometheus.enabled="false"
# 설치 상태 확인
kubectl get pod -n kubecost
NAME READY STATUS RESTARTS AGE
kubecost-cost-analyzer-9f75ffc6b-9dww8 2/2 Running 0 80s
kubecost-kube-state-metrics-d6d9b7594-hwzgd 1/1 Running 0 80s
kubecost-prometheus-server-7755c9b669-l8hs5 1/1 Running 0 80s
# LoadBalancer에 연결하여 업데이트
cat <<'EOF' |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kubecost-alb-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/scheme: internet-facing
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubecost-cost-analyzer
port:
number: 9090
EOF
(export NAMESPACE=kubecost && kubectl apply -n $NAMESPACE -f -)
# DNS 연결
export ENDPOINT=$(kubectl get ingress kubecost-alb-ingress -n kubecost --output jsonpath='{.status.loadBalancer.ingress[0].hostname}')
echo "Kubecost UI DNS name: ${ENDPOINT}"
Kubecost UI DNS name: k8s-kubecost-kubecost-7931dc7581-278425107.ap-northeast-2.elb.amazonaws.com
kubectl annotate ingress kubecost-alb-ingress -n kubecost "external-dns.alpha.kubernetes.io/hostname=kubecost.$MyDomain"
ingress.networking.k8s.io/kubecost-alb-ingress annotated
echo -e "kubecost URL = http://kubecost.$MyDomain"
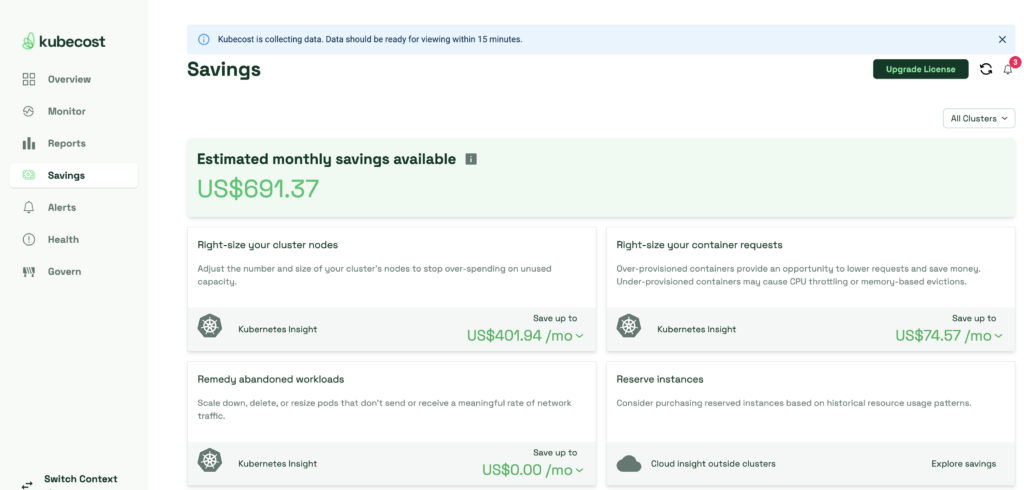
kubecost URL = http://kubecost.bs-yang.comkubecost 설치와 Loadbalancer 연결이 제대로 됐다면 아래와 같이 대쉬보드가 호출되는 것을 알 수 있다.
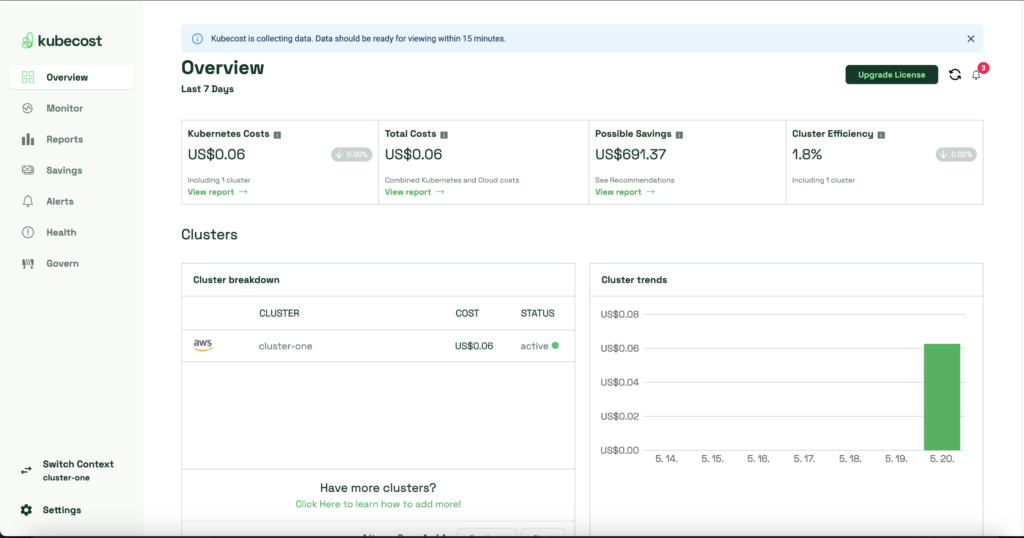
클러스터 배포와 kubecost 수집 자체가 얼마 되지 않아서 자세한 데이터들을 볼 수는 없지만 화면을 여기저기 클릭하면서 데이터를 확인할 수 있었다.
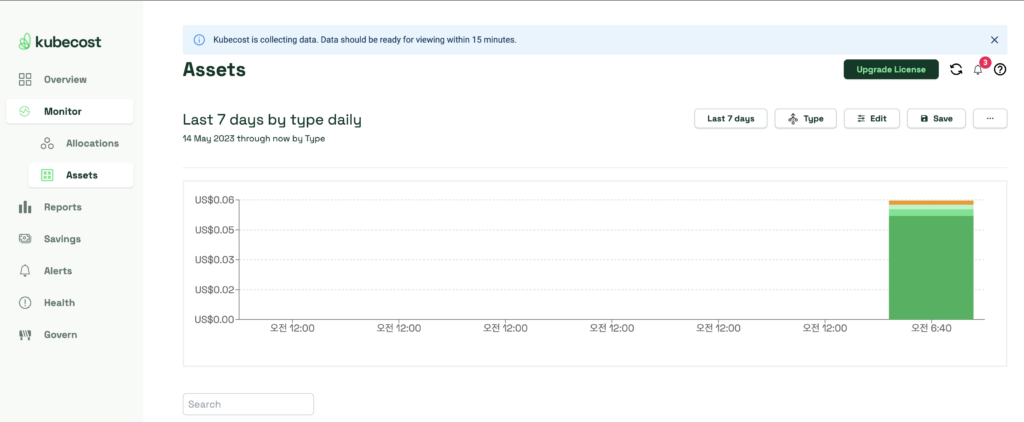
8. 정리
kOps에서 다뤘던 내용들이 있어서 이번에는 많이 어렵지 않게 실습을 진행할 수 있었다. 그라파나에서 이미지를 포함한 알림을 보내고 싶었지만 사용하고 있는 계정이 회사 계정이라 정책상 S3 Public Access을 허용할 수 없어서 테스트하지 못해 아쉽다. 추후 개인계정에서 테스트해볼 수 있으면 좋을 것 같다.