이번 주제는 테라폼 워크플로와 파이프라인에 대해 다뤄볼 예정이다.
1. 워크플로
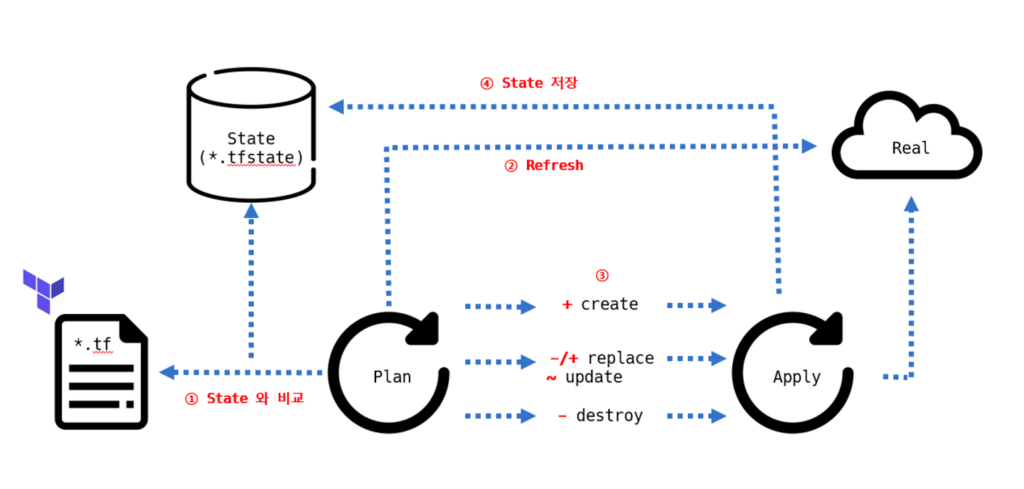
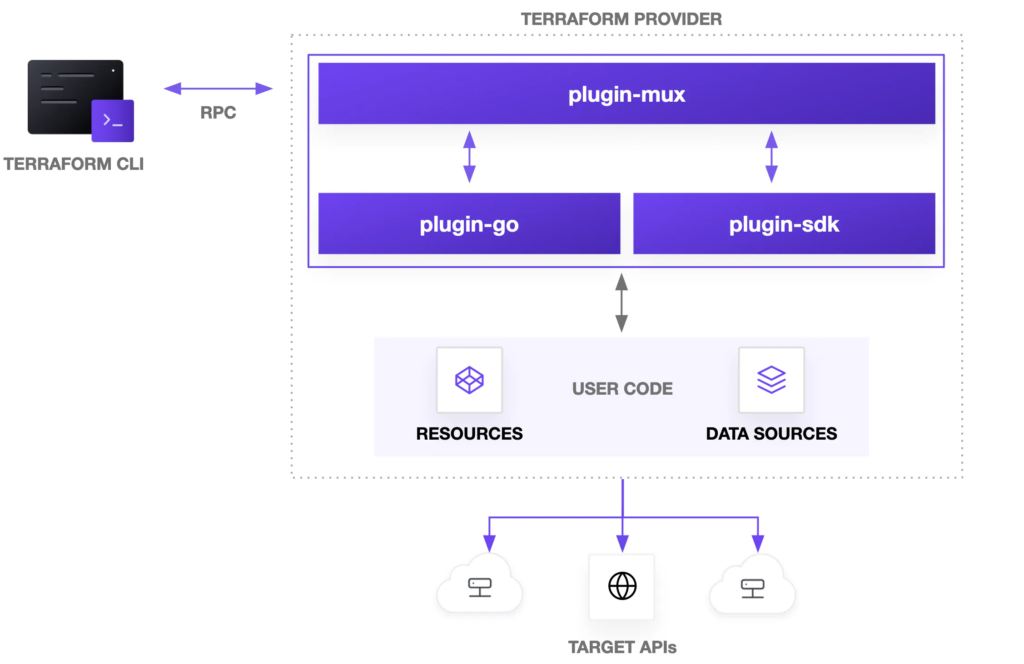
Terraform은 인프라스트럭처를 코드로 작성하고 관리할 수 있게 해주는 도구로, 일련의 명확한 워크플로를 제공한다. 이 워크플로를 따르면 사용자는 안정적이고 반복 가능한 방식으로 클라우드 리소스를 배포하고 변경할 수 있다. Terraform 워크플로는 크게는 Write, Plan, Apply로 구성되지만 상세한 단계는 다음 단계들로 구성된다.
초기화 (Initialization): Terraform 작업 디렉토리를 초기화한다. 명령어는 terraform init을 사용한다. 이 단계에서는 Terraform 설정 파일과 필요한 프로바이더 플러그인을 로드하고 프로바이더는 AWS, Azure, GCP 등과 같은 여러 클라우드 서비스에 대한 API 호출을 수행하게 된다.
코드 작성(Write): 사용자는 *.tf 파일에 IaC을 작성한다. 이 코드는 사용하려는 리소스, 설정 및 프로바이더 정보를 정의한다.
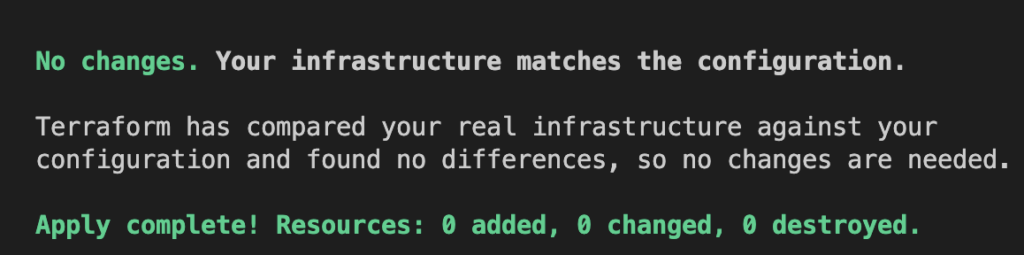
실행 계획 (Plan): 명령어로는 terraform plan을 사용한다. 현재 상태와 Terraform 코드를 비교하여 변경 사항을 표시한다. 이는 “예비 실행”과 같으며 실제 리소스에는 변경사항이 적용되지 않는다. 사용자는 이 단계에서 어떤 변경이 발생할지 미리 확인할 수 있다.
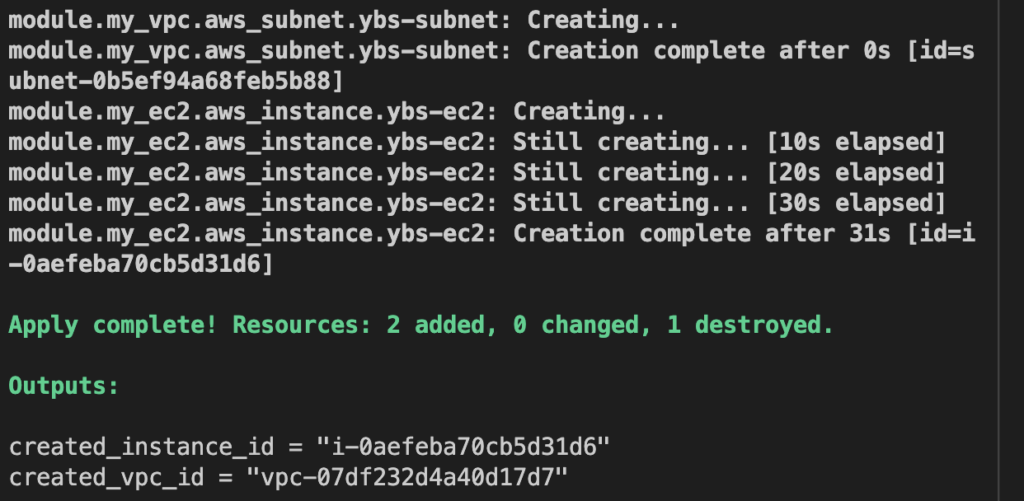
적용 (Apply): 명령어로는 terraform apply을 사용한다. 실행 계획에서 제시된 변경 사항을 실제 리소스에 적용한다. 사용자는 변경 사항을 승인한 후에만 이를 적용할 수 있다.
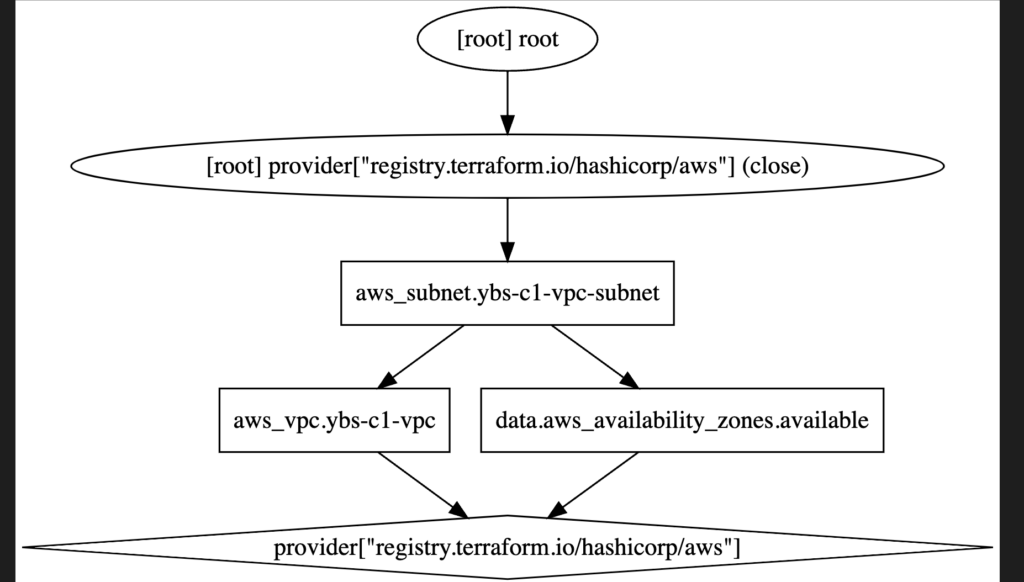
상태 관리 (State Management): Terraform은 .tfstate 파일에 리소스의 현재 상태를 저장한다. 이 상태 파일을 통해 Terraform은 실제 리소스와 Terraform 코드 사이의 매핑을 관리한다.
변수와 출력: variables.tf와 outputs.tf 파일을 사용하여 입력 변수를 정의하고 결과 출력을 관리할 수 있다.
모듈: 복잡한 인프라 구성을 모듈로 분리하여 코드 재사용성을 향상시킬 수 있다.
제거 (Destroy): terraform destroy: Terraform 코드에 정의된 리소스를 제거한다.
위 워크플로에 따라 Terraform은 선언적인 방식으로 인프라를 구성하고 관리할 수 있게 해준다. 사용자는 원하는 최종 상태만을 정의하면 되며, Terraform은 이를 실제 인프라에 반영하는데 필요한 모든 단계를 처리한다.
2. 워크플로 구분
워크플로는 단순하지만 개인과 다수 작업자에 따라 조금 내용이 달라질 수 있다.
개인 워크플로 (Individual Workflow):
- 이 워크플로는 개발자나 관리자가 혼자 작업할 때 적합하다.
- Terraform 코드를 로컬 시스템에서 직접 실행하게 된다.
- Terraform 상태 파일도 로컬에 저장될 수 있다.
- 이런 방식은 간단한 프로젝트나 테스트, 프로토타이핑 등에 적합하다.
단계:
terraform init: 초기화
terraform plan: 변경 사항 미리보기
terraform apply: 변경 사항 적용
필요한 경우, terraform destroy로 리소스 제거
다중 작업자 워크플로 (Team Workflow):
- 팀이나 조직에서 여러 사람이 함께 작업할 때 사용되는 워크플로이다.
- 상태 파일은 원격 스토리지(예: Amazon S3, Terraform Cloud)에 저장되어 여러 사람이 공유할 수 있게 된다.
- 원격 스토리지를 사용하면 상태 파일의 동시 변경을 방지하는 락 기능을 활용할 수 있다.
- Terraform Cloud나 Terraform Enterprise는 협업 기능과 함께 실행 환경, 상태 관리, 모듈 저장소 등의 추가 기능을 제공한다.
단계:
원격 스토리지 및 락 설정: Terraform 설정에서 backend를 사용하여 원격 스토리지를 지정합니다.
terraform init: 초기화 시 원격 스토리지에 연결
terraform plan: 변경 사항 미리보기
terraform apply: 변경 사항 적용
필요한 경우, terraform destroy로 리소스 제거
주의사항:
여러 작업자가 동시에 Terraform을 실행하지 않도록 주의해야 한다. 또한, 락 기능을 활용하여 동시 변경을 방지할 수 있다.
모든 팀원이 동일한 Terraform 버전을 사용하는 것이 좋다.
코드 리뷰, 버전 관리 (예: Git) 및 CI/CD 파이프라인과 같은 현대적인 개발 워크플로를 함께 사용하는 것이 좋다.
3. 격리
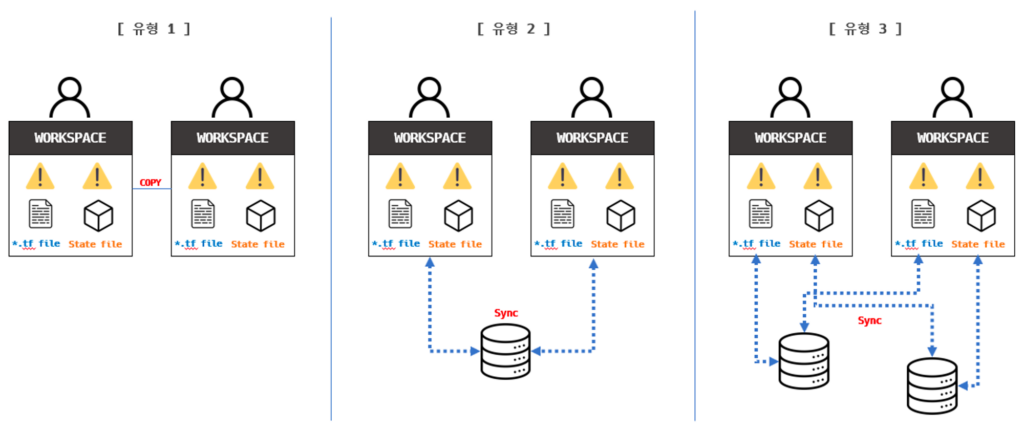
Terraform에서의 “격리”는 주로 Terraform 상태, 리소스, 구성 요소를 서로 독립적으로 관리하고 운영하기 위한 구조와 워크플로를 의미한다. 협업을 할 때 격리 구조를 설계하지 않으면 여러 문제점이 발생할 수 있다. 격리는 여러 목적으로 사용될 수 있으며, 주로 다음과 같은 이유로 필요하다.
- 환경별 분리: 개발, 스테이징, 프로덕션과 같은 다양한 환경을 독립적으로 관리하고 운영하려면 해당 환경별로 리소스와 상태를 분리해야 한다.
- 작업 영역 분리: 다양한 팀이나 프로젝트, 애플리케이션 등에 대한 작업을 독립적으로 수행하려면 해당 영역별로 리소스와 상태를 분리해야 한다.
- 변경의 최소화: 특정 구성 요소나 서비스에 변경이 발생했을 때, 그 영향을 해당 부분에 국한시켜 다른 부분에 영향을 주지 않도록 하기 위해 필요하다.\
Terraform에서 격리를 달성하는 주요 방법은 다음과 같다.
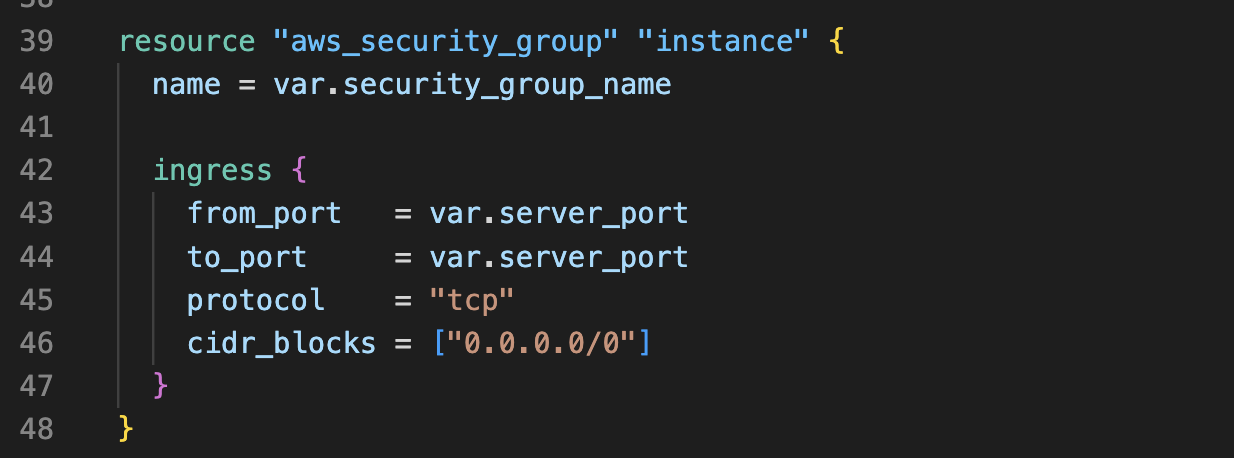
- 스테이트 격리: Terraform 상태 파일(
terraform.tfstate)을 통해 리소스의 현재 상태를 추적한다. 다양한 환경이나 작업 영역에서 독립적인 상태 관리를 위해 각각의 상태 파일을 분리할 수 있다. 원격 스토리지(예: Amazon S3)를 사용하면 각 환경별로 별도의 버킷 또는 경로에 상태 파일을 저장하여 격리할 수 있다. - 워크스페이스 사용: Terraform은 워크스페이스라는 기능을 제공하여 다양한 환경을 동일한 구성 내에서 격리할 수 있다. 각 워크스페이스는 고유한 상태를 가지며, 환경 변수를 통해 다른 환경의 설정 값을 제공할 수 있다.
- 모듈화: Terraform 모듈을 사용하면 코드를 재사용 가능한, 독립적인 단위로 분리할 수 있다. 이를 통해 리소스와 구성 요소를 독립적으로 관리하고 테스트할 수 있다.
- 환경 구성 분리: 다양한 환경(예: 개발, 스테이징, 프로덕션)에 대한 구성을 별도의 파일이나 디렉토리로 분리하여, 환경별로 다른 변수와 설정 값을 제공할 수 있다.
4. 프로비저닝 파이프라인 설계
스터디 실습에서는 Github Action과 Terraform Cloud 등을 사용하는 예제를 썼지만 나는 업무에 사용해봤던 AWS Code Commit/Pipeline/Build을 사용하려고 한다.
4.1 CodeCommit 생성
AWS Console에서 Code Commit 메뉴를 검색해 들어간 뒤 레포지토리 생성을 클릭한다.
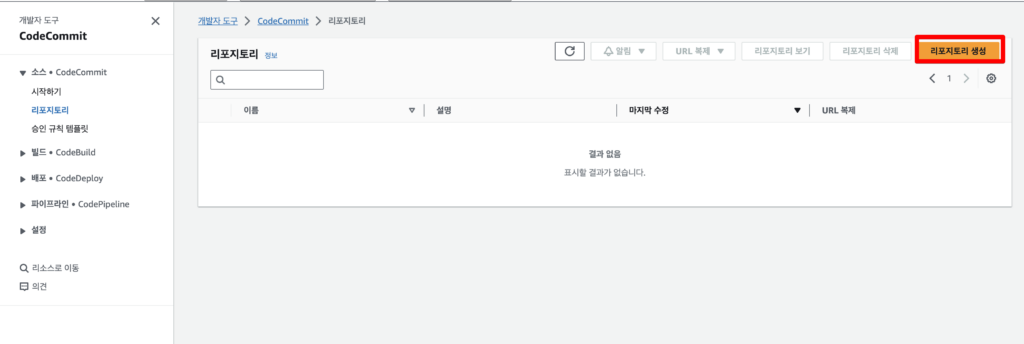
리포지토리 이름을 입력하고 생성 버튼을 클릭한다.
생성은 거의 곧바로 완료되고 아래와 같은 화면을 확인할 수 있다.
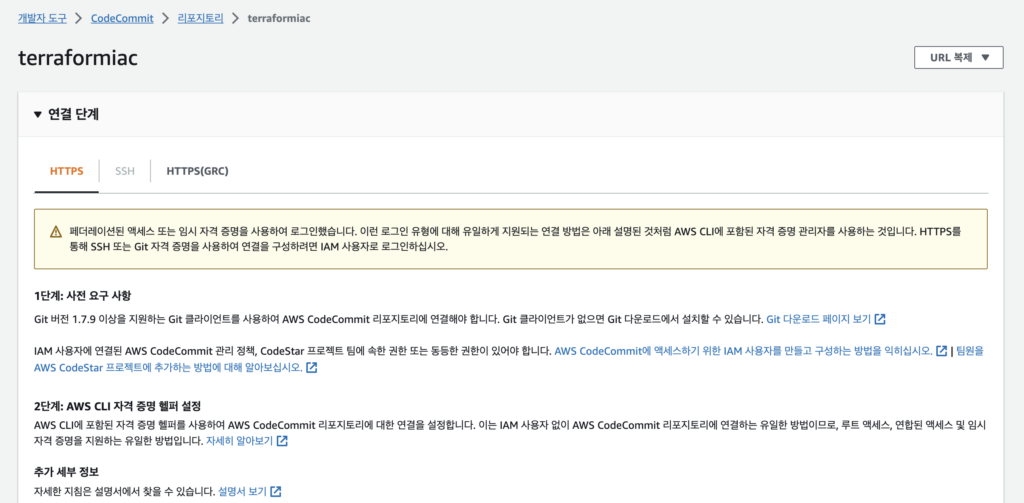
vscode에서 CodeCommit에 push 등을 하기 위해 자격증명을 진행한다. 이때 IAM User을 사용했고 해당 User에는 AWSCodeCommitFullAccess 정책을 연결해주었다.
이후 해당 사용자에 대해 자격 증명 생성을 위해 IAM Console에서 해당 사용자에 대해 AWS CodeCommint에 대한 HTTPS Git 자격 증명 생명을 진행해주었다.

HTTPS(GRC)을 통해 연결하기 위해서 macOS에 git-remote-codecommit을 설치했다.
다른 계정과 충돌되지 않기 위해 aws configure –profile을 통해 별도 프로파일로 진행하였다
HTTPS(GRC) 복제를 한다.
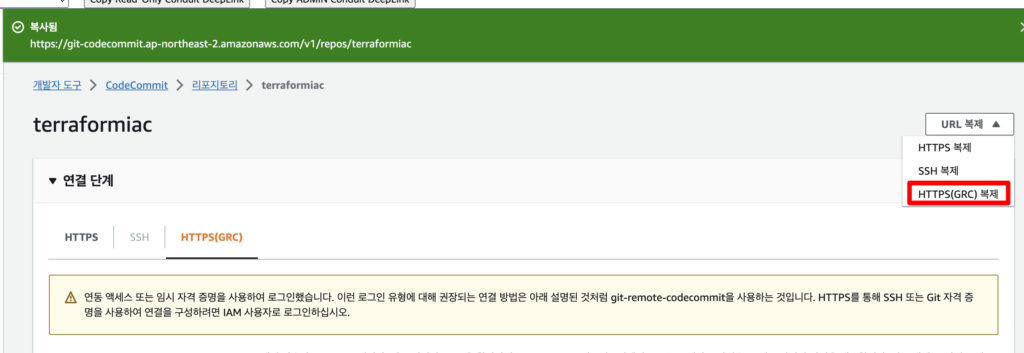
git clone 명령어를 통해 vscodedㅔ서 코드를 작성 중인 폴더와 레포지토리 클론을 진행한다.

4.2 CodeBuild 생성
코드 빌드 및 테스트를 위해 Code Build을 생성한다. 빌드를 진행하기 전에 위에서 만든 CodeCommit에 브랜치 정보 확인이 가능해야 하기 때문에 사전에 readme.md 같은 파일 하나만이라도 push을 진행해주면 좋다.
# readme.md 작성
vi readme.md
# git push
git add -A
git commit -m 'Initial checkin'
git push
오브젝트 나열하는 중: 3, 완료.
오브젝트 개수 세는 중: 100% (3/3), 완료.
오브젝트 쓰는 중: 100% (3/3), 229 bytes | 229.00 KiB/s, 완료.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote: Validating objects: 100%
To codecommit::ap-northeast-2://terraformiac
* [new branch] master -> masterAWS Console에서 CodeBuild 선택 후 프로젝트 만들기를 클릭한다.

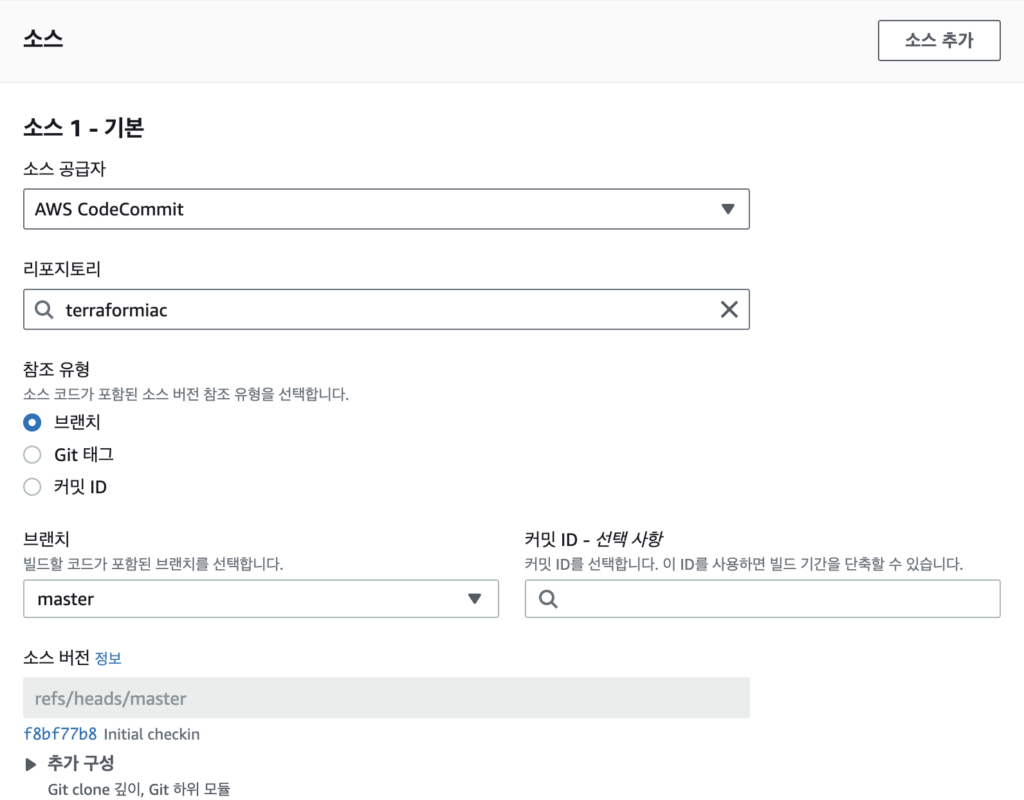
빌드 프로젝트 이름 설정과 소스 설정을 진행해준다. 소스는 위에서 만든 CodeCommit과 브랜치를 선택해준다.
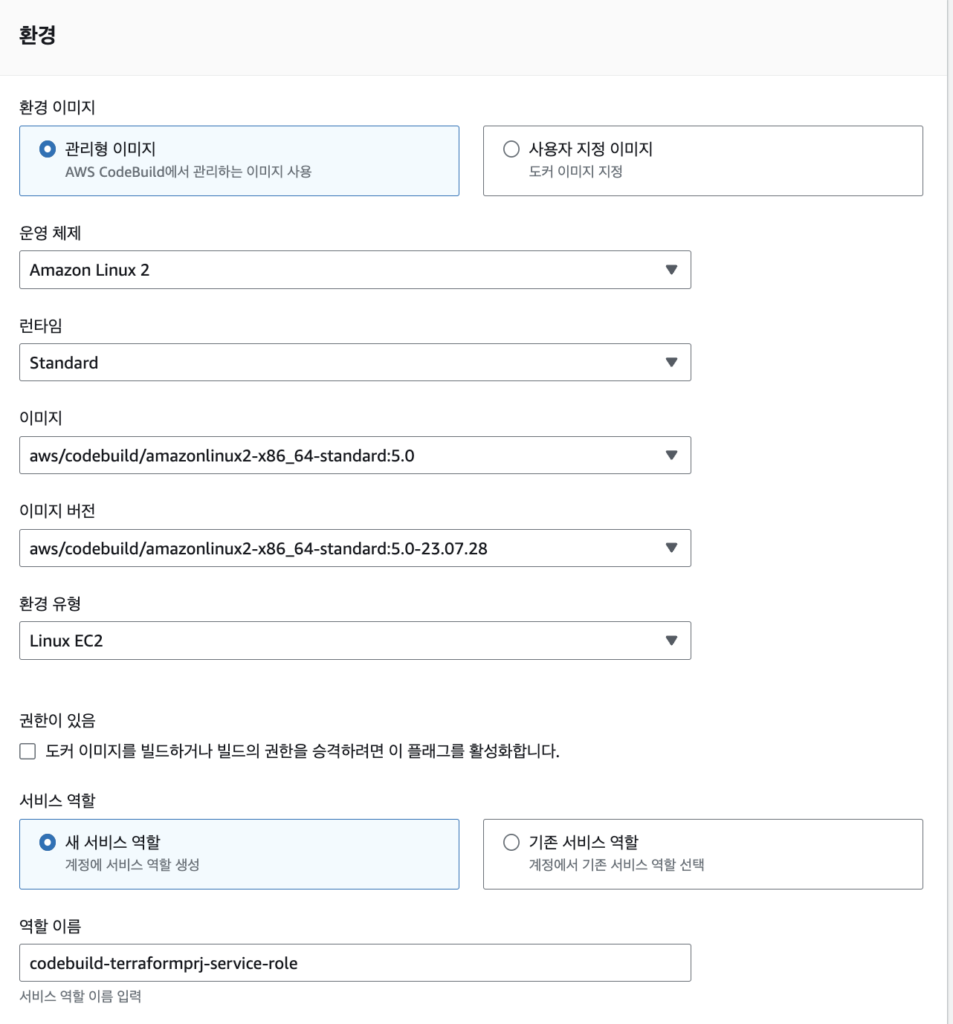
환경에 대한 내용도 작성해준다. 특별하게 필요한 내용이 없기 때문에 간단하게 설정해준다.
추가로 입력해줄 내용이 없으면 프로젝트 빌드 생성을 눌러준다.
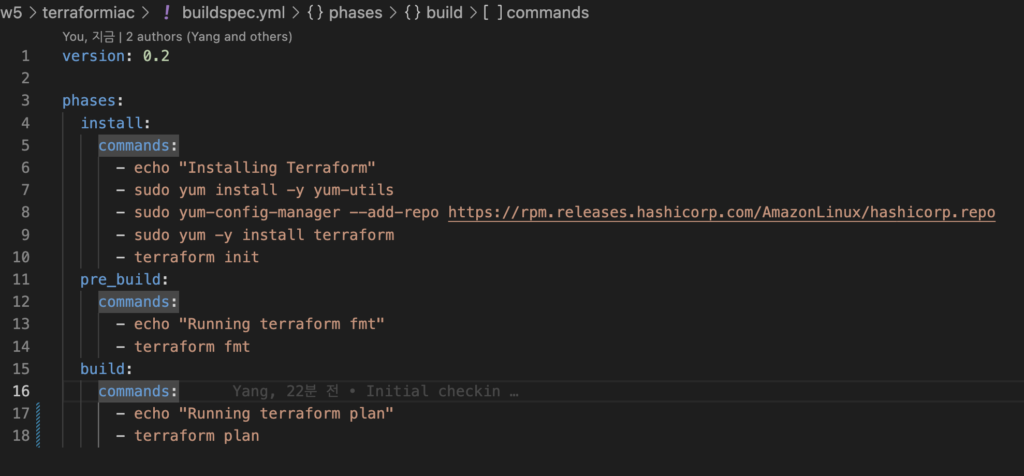
빌드가 돌 때 Terraform 설치 및 init/plan을 하기 위해 buildspec 파일을 작성해준다.
#buildspec.yml
version: 0.2
phases:
install:
commands:
- echo "Installing Terraform"
- sudo yum install -y yum-utils
- sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo
- sudo yum -y install terraform
- terraform init
pre_build:
commands:
- echo "Running terraform fmt"
- terraform fmt
build:
commands:
- echo "Running terraform plan"
- terraform plan
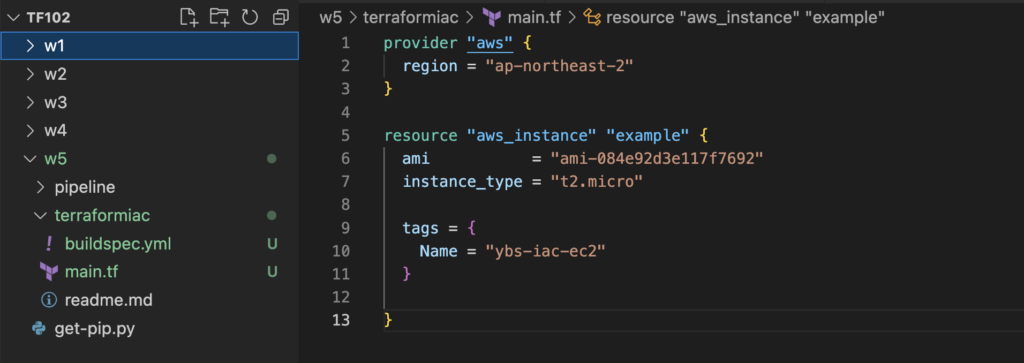
4.3 Code 작성
테스트는 EC2 배포하는 것으로 진행할 예정이니 간단하게 EC2 작성하는 코드를 작성하고 Push까지 진행해본다.
# main.tf
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_instance" "example" {
ami = "ami-084e92d3e117f7692"
instance_type = "t2.micro"
tags = {
Name = "ybs-iac-ec2"
}
}
#git push 진행
git add -A
git commit -m 'Initial checkin'
git push
오브젝트 나열하는 중: 5, 완료.
오브젝트 개수 세는 중: 100% (5/5), 완료.
Delta compression using up to 10 threads
오브젝트 압축하는 중: 100% (4/4), 완료.
오브젝트 쓰는 중: 100% (4/4), 691 bytes | 691.00 KiB/s, 완료.
Total 4 (delta 0), reused 0 (delta 0), pack-reused 0
remote: Validating objects: 100%
To codecommit::ap-northeast-2://terraformiac
f8bf77b..0c7981d master -> master
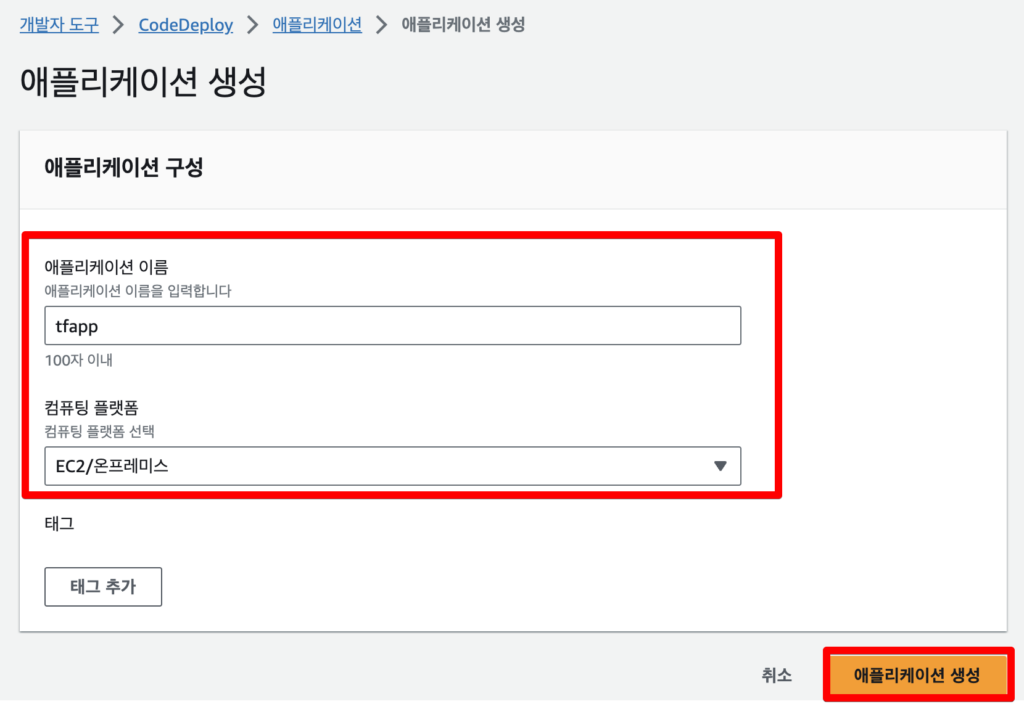
4.4 CodeDeploy/Pipeline 생성
Commit/Build를 만들었다면 deploy와 pipeline을 생성해준다.
CodeDeploy을 먼저 만들어준다. 간단하게 이름과 EC2를 선택해주고 생성을 누른다.
deploy 단계에서 작동할 appspec.yml파일을 작성해준다. 이때 build와는 다르게 apply도 같이 진행해준다.
#appspec.yml
version: 0.0
os: linux
files:
- source: /
destination: /home/ec2-user/terraform/
hooks:
ApplicationStart:
- location: scripts/run_build.sh
timeout: 300
runas: root
#ipts/run_build.sh
#!/bin/bash
terraform -chdir=/home/ec2-user/terraform/ init
terraform -chdir=/home/ec2-user/terraform/ apply -auto-approve그 다음 pipeline을 만들어준다. 파이프라인의 이름을 간단하게 작성하고 다음을 누른다.
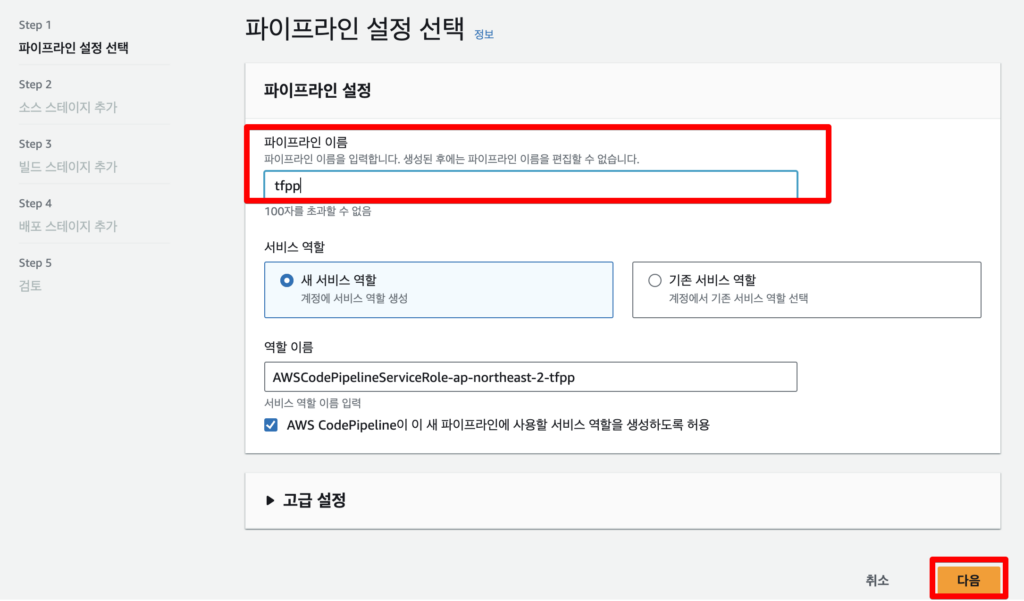
소스는 위에서 만든 codecommit과 브랜치를 선택해주고 다음을 누른다.
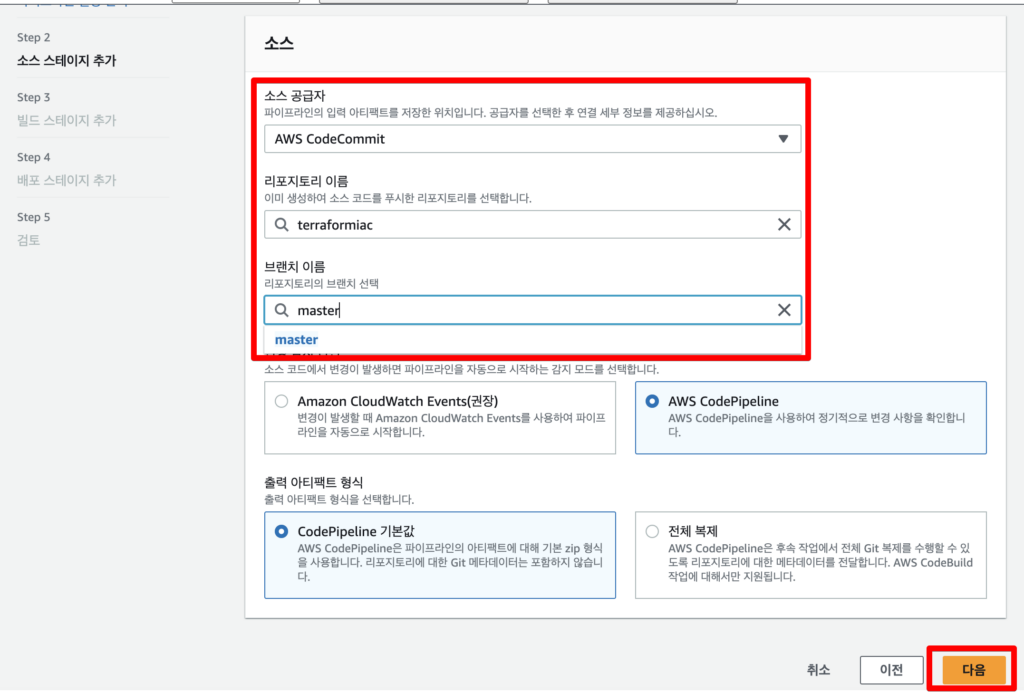
빌드 또한 위에서 만든 build 값을 입력해준다.
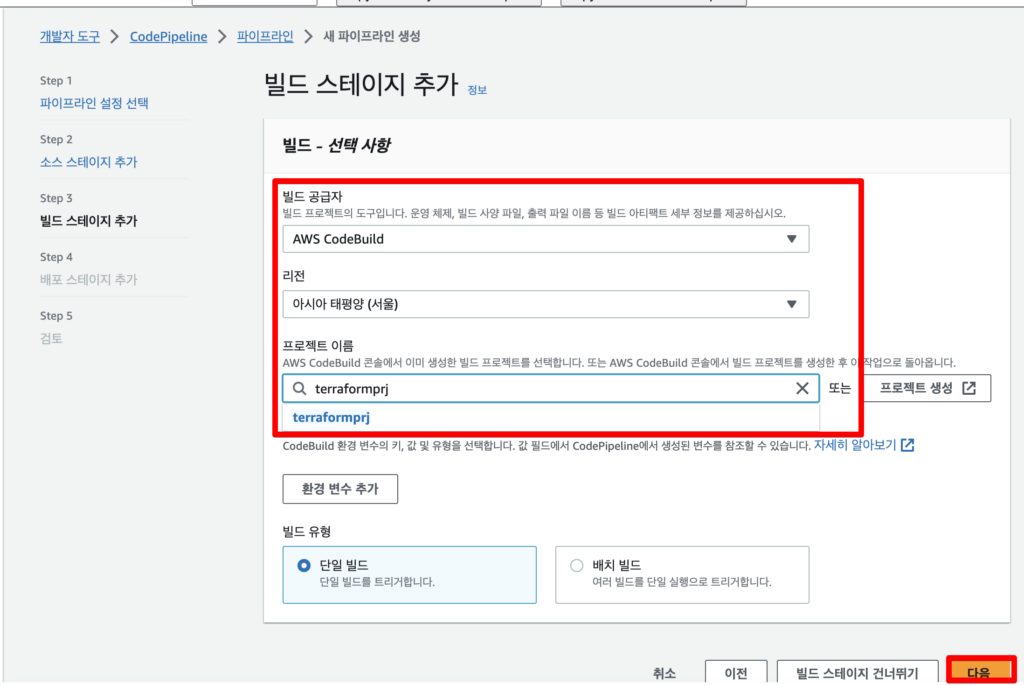
배포 스테이지는 위에서 만든 Deploy Application 정보를 입력해준다. (배포 그룹은 간단하게 만들 수 있으니 만들어서 넣어준다.)
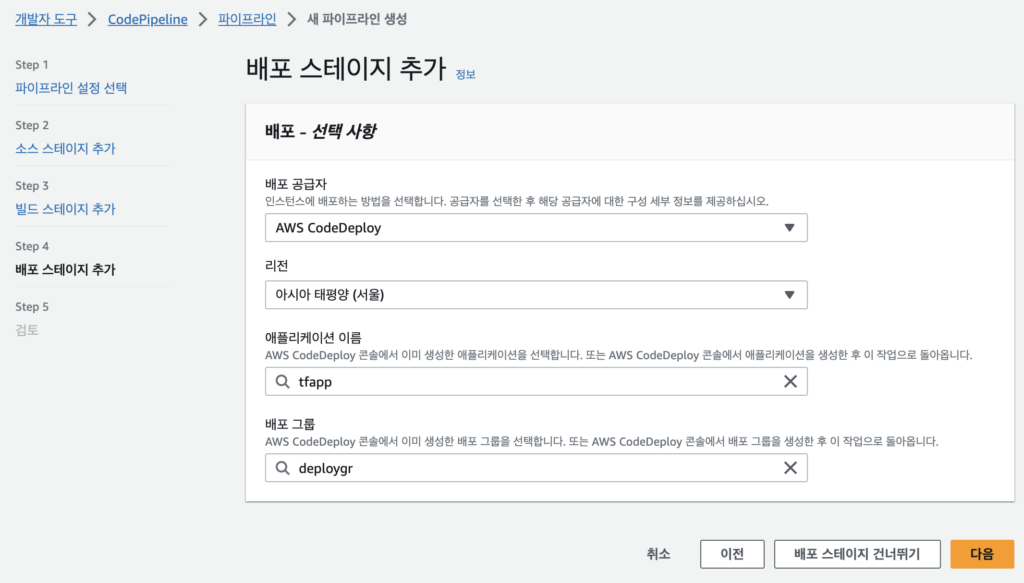
그 후 별다른 수정사항이 없으면 파이프라인 생성을 눌러 생성을 진행한다.
파이프라인이 잘 생성되면 알아서 최초 1회 실행되는 것을 확인할 수 있다.
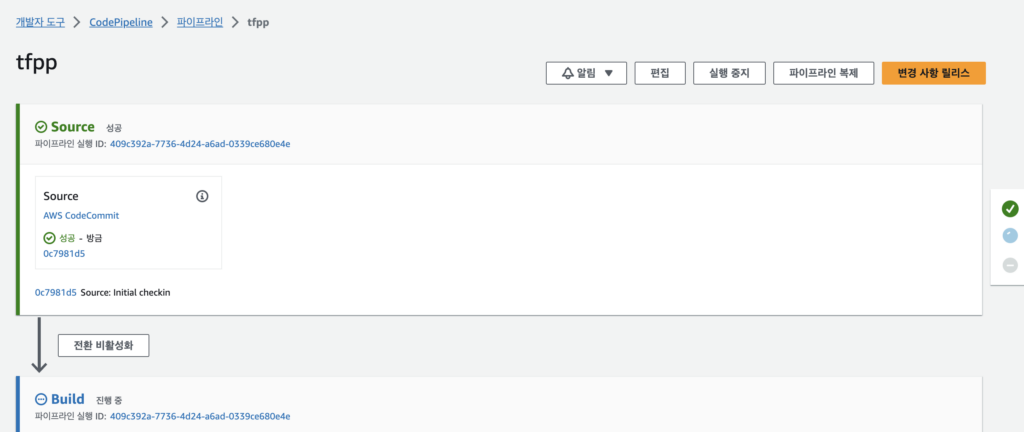
Build 단계에서 실패가 떴다.
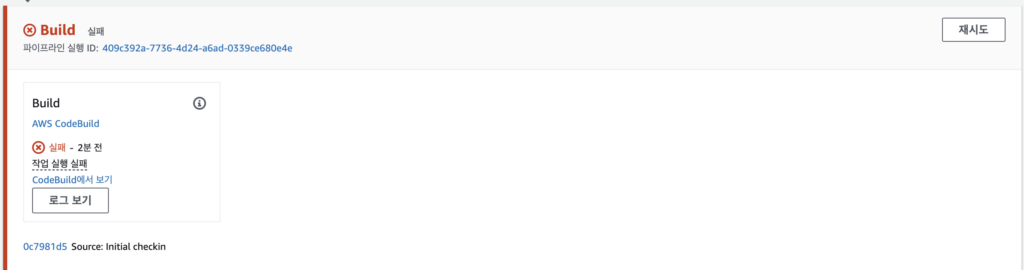
원인을 찾아보니 EC2 생성하는 권한이 없어서 오류가 발생한 것으로 보인다. 권한을 추가해주고 다시 실행을 시켰다.
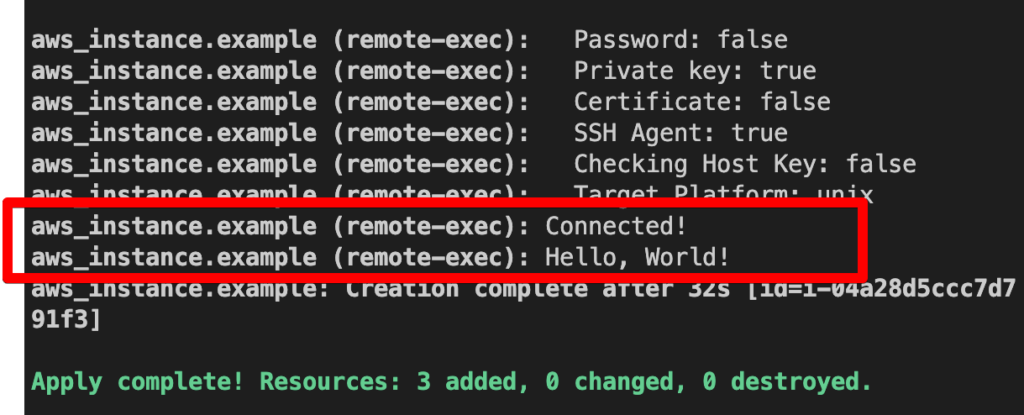
작은 몇 가지 트러블 슈팅을 진행하면서 정상적으로 돌아가기를 기다렸다.
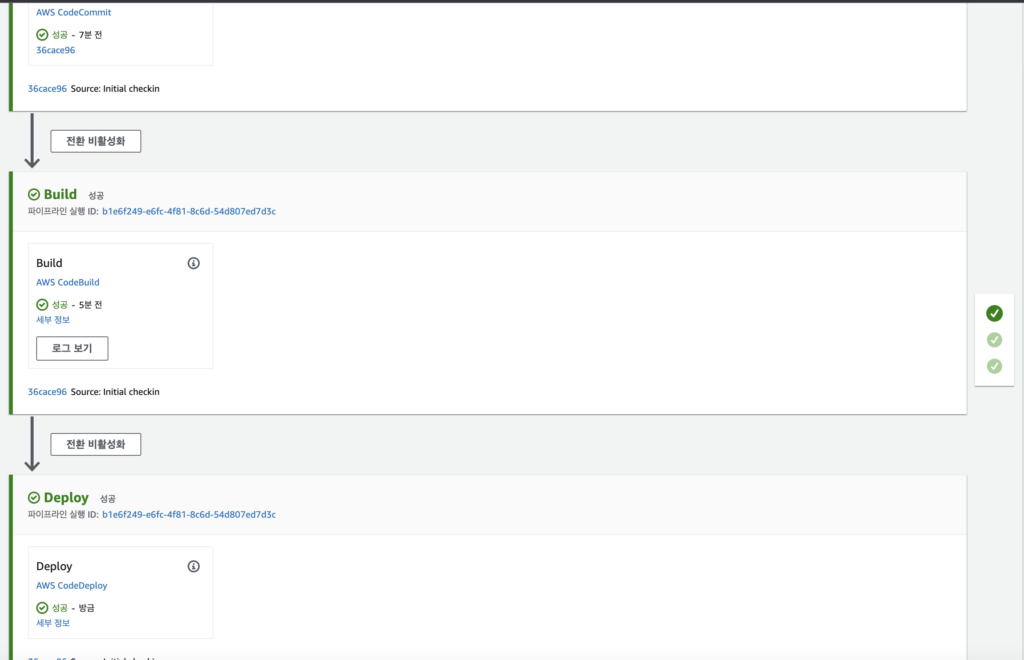
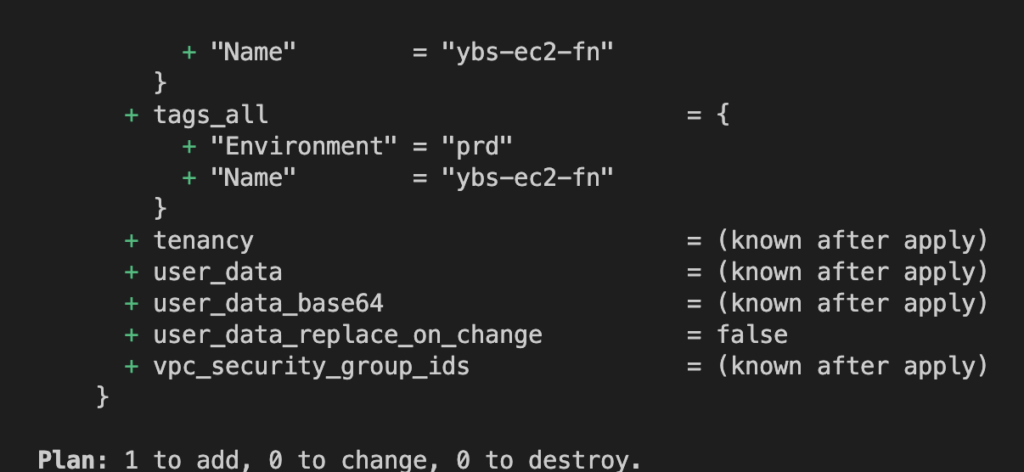
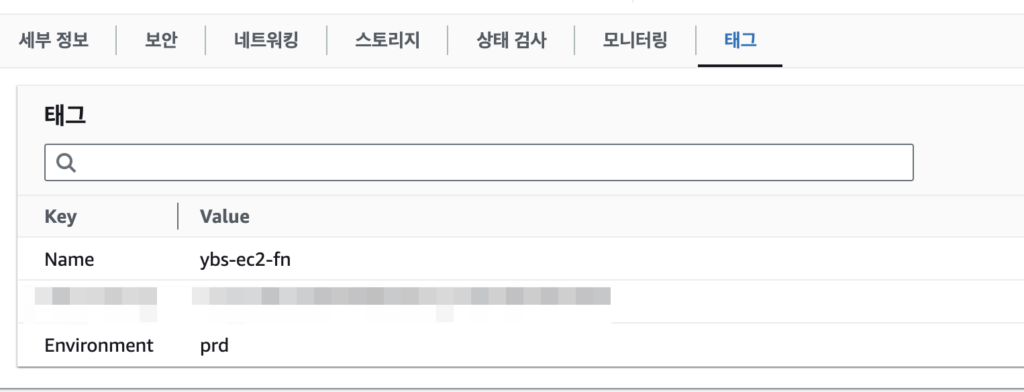
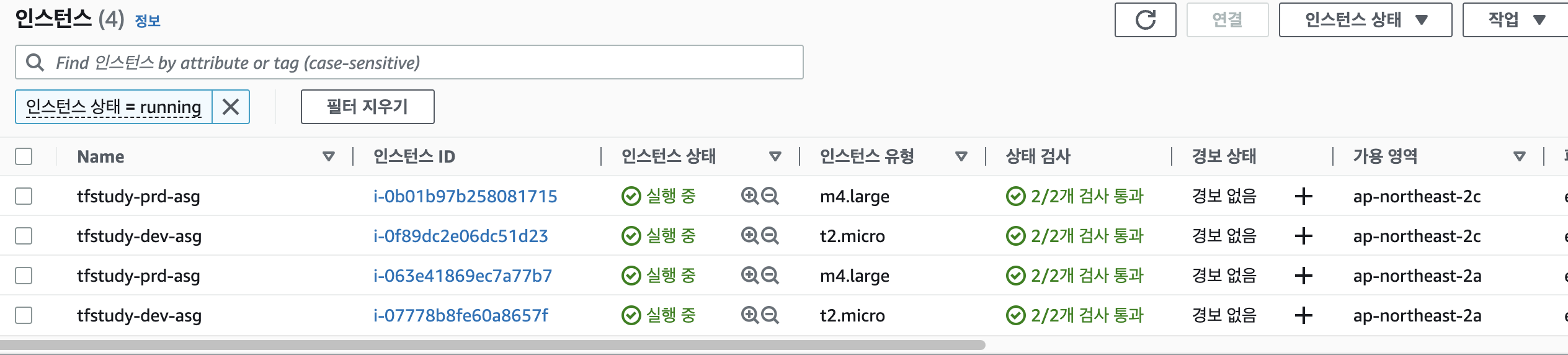
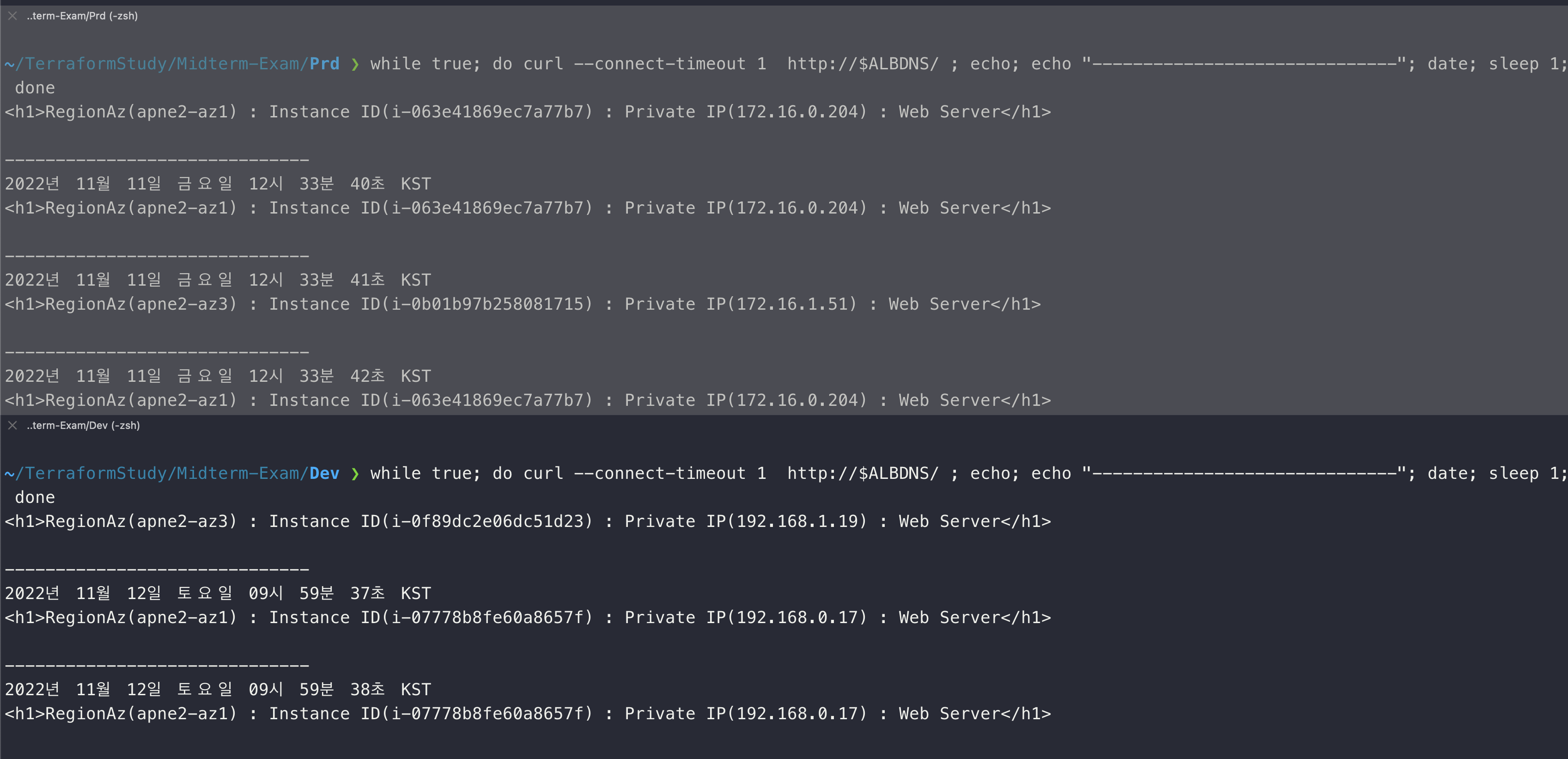
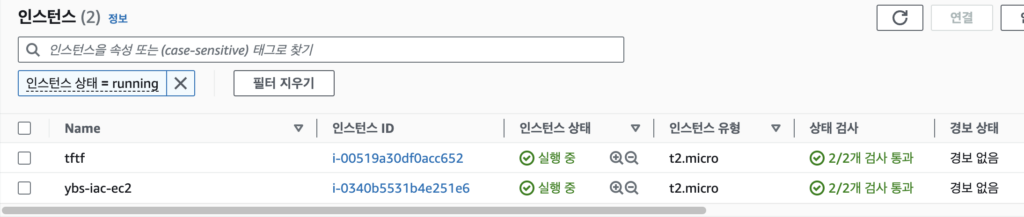
EC2가 제대로 배포된 것을 확인할 수 있다.
5. 정리
이번 시간에는 워크플로와 나름의 파이프라인을 작성해서 테스트를 해보았다. 파이프라인은 프로젝트를 통해 조금은 익숙해졌다고 생각했는데 Role마다 넣어줘야 하는 권한들이 있어 자잘한 트러블슈팅이 꽤 많은 시간을 잡아먹은 거 같다. 그래도 AWS 네이비트 요소들로 테스트할 수 있어서 나름의 도움이 된 거 같다.